
Now lets practice again and again past Interview Questions for Java and related technologies, which will help you to clear your interview.

Question: What is the Deadlock, give example?
Answer: Deadlock refers to a situation in which two or more threads are blocked forever, each waiting for the other to release a lock. For example, imagine two threads, A and B. Thread A holds a lock on resource 1 and is waiting for a lock on resource 2, while Thread B holds a lock on resource 2 and is waiting for a lock on resource 1. Neither can proceed, leading to a deadlock.
Question: How can you avoid deadlock?
Answer: Deadlock can be avoided by following certain strategies:
- Lock Ordering: Always acquire the locks in a consistent, predefined order.
- Lock Timeout: Specify a timeout while trying to acquire a lock, and back off if the lock isn’t obtained in time.
- Deadlock Detection: Use algorithms to detect deadlock situations and then break the deadlock.
- Nested Locks: Ensure that once a thread holds one lock, it doesn’t try to hold another.
Question: What is live lock and how can you avoid it?
Answer: Livelock is a situation where two or more threads continually repeat a set of actions in response to changes in the other thread but never make progress. It's like two people trying to pass each other in a corridor, but they keep moving in the same direction at the same time. To avoid livelock: Introduce randomness in decision making or use back-off mechanisms where a thread waits or retries after random intervals.
Question: What is the difference between runtime and compile time?
Answer: Compile-time refers to the time when a program is being compiled, and any errors or issues at this phase are compile-time errors. Runtime, on the other hand, is when the program is actually being executed, and any issues at this phase are runtime errors.
Question: Explain each data structure in Java like List, Set, Graph and Map?
Answer:
- List: An ordered collection of elements allowing duplicates. Examples include ‘ArrayList’ and ‘LinkedList’.
- Set: A collection that doesn’t allow duplicates. Examples include ‘HashSet’, ‘LinkedHashSet’, and ‘TreeSet’.
- Graph: Not part of the standard Java library, but it represents a set of nodes connected by edges. Typically implemented using adjacency matrices or adjacency lists.
- Map: Represents key-value pairs, where each key maps to a single value. Examples include ‘HashMap’, ‘LinkedHashMap’, and ‘TreeMap’.
Question: What is the difference between a LinkedList and ArrayList, which one would you prefer in which scenario?
Answer: ‘LinkedList’ is a doubly-linked list implementation while ‘ArrayList’ is backed by an array. ‘LinkedList’ offers better performance for add/remove operations at the beginning or middle, whereas ‘ArrayList’ offers faster access times for indexed retrieval. Prefer ‘ArrayList’ when frequent access of elements is required, and ‘LinkedList’ when frequent insertion/deletion operations occur.
Question: Design a vending Machine Algorithm which can support different items and currency?
Answer: A vending machine algorithm would involve:
- A product catalog with their prices.
- A currency detector and validator to accept and validate coins/bills.
- A mechanism to select products.
- A mechanism to calculate the total amount inserted and return change if needed.
- A dispenser to release the selected product.
To support different items and currency, the machine should be configurable to load various product details and understand multiple currency denominations.
Question: How do you differentiate encoding, encryption, and hashing?
Answer:
- Encoding: Transforming data into another format using a scheme that is publicly available, like Base64. It’s reversible.
- Encryption: Transforming data to keep it secret from unauthorized users. It uses a key and is reversible if you have the key.
- Hashing: Converting data into a fixed-size string of characters, which is typically a digest. It’s a one-way transformation and not reversible.
Question: What is Race Condition and how can you resolve it?
Answer: A race condition occurs when two or more threads can access shared data and they try to change it at the same time. Since the outcome depends on the order in which the threads execute, it's unpredictable. Resolving race conditions typically involves ensuring that only one thread can access the shared resource at a time. This is usually achieved using synchronization mechanisms like locks, mutexes, or semaphores.
Question: What is Synchronized block and Lock?
Answer: A ‘synchronized’ block in Java provides a way to ensure that only one thread can access a particular resource at a time. It's used to guard against race conditions. A ‘Lock’, on the other hand, is a more flexible and powerful synchronization mechanism provided by the ‘java.util.concurrent. locks’ package. Unlike ‘synchronized’, ‘Lock’ provides additional capabilities like timeout while waiting for a lock, non-blocking acquirement, and more.
Question: Which occupies more space LinkedList or ArrayList?
Answer: ‘LinkedList’ typically occupies more space than ‘ArrayList’. In a ‘LinkedList’, each element requires additional space for two references (next and previous), whereas in ‘ArrayList’, the elements are stored in a contiguous memory location backed by an array.
Question: What is ConcurrentHashMap and how it differs from Hashtable?
Answer: ‘ConcurrentHashMap’ is a part of the ‘java.util. concurrent’ package and allows for concurrent reads and a limited number of concurrent writes. Unlike ‘Hashtable’, which locks the entire map for any write operation, ‘ConcurrentHashMap’ only locks a segment or a bucket, allowing for higher concurrency and better performance in multi-threaded environments.
Question: What is your first option when you get OutOfMemoryError on production application?
Answer: The first step when encountering an ‘OutOfMemoryError’ is to capture heap dumps and analyze them using tools like Eclipse MAT or VisualVM. This helps in identifying memory leaks or any excessive object allocations.
Question: What is the Heap and Stack Memory?
Answer: Heap memory is where Java runtime instances are allocated. It is used for dynamic memory allocation for Java objects and JRE classes. Stack memory, on the other hand, is used for execution of a thread. It contains method specific values, local variables, and reference variables.
Question: Can you explain the internal working of the HashMap?
Answer: At a high level, ‘HashMap’ stores entries (key-value pairs) in buckets. When you provide a key, it computes a hash for the key and determines the bucket where the entry should be stored. If two different keys produce the same hash, a linked list of entries is used for that bucket. In Java 8, if the number of items in a bucket exceeds a threshold, the linked list is transformed into a balanced tree to improve performance.
Question: What is HashMap and ArrayList?
Answer: ‘HashMap’ is a part of the Java Collections Framework and is used for storing key-value pairs. ‘ArrayList’ is a dynamically resizing array, also part of the Collections Framework, which can store ordered elements and allows for indexed access.
Question: Can you tell me new Java-8 features?
Answer: Java 8 introduced several new features including Lambda Expressions, Stream API, Default and Static methods in interfaces, Optional class, new Date and Time API, and the ‘java.util.function’ package with interfaces like ‘Predicate’, ‘Function’, ‘Consumer’, and ‘Supplier’.
Question: What is Parallel Stream in Java?
Answer: Parallel streams in Java 8 are a variant of the Stream API that allows processing elements in parallel, leveraging multiple processors/cores available in the system. They can be easily created using ‘stream.parallel()’ or ‘Collection.parallelStream()’.
Question: Can you explain these three things in Java, Supplier, Consumer and Predicate?
Answer: These are functional interfaces introduced in Java 8.
- ‘Supplier
- ‘Consumer
- ‘Predicate
Question: Can you explain the Spring Bean Lifecycle?
Answer: The Spring Bean Lifecycle involves several stages:
- Bean instantiation
- Populating properties
- Calling the ‘setBeanName’ method of ‘BeanNameAware’
- Calling the ‘setBeanFactory’ method of ‘BeanFactoryAware’
- Pre-initialization: ‘BeanPostProcessors’ are applied.
- ‘afterPropertiesSet’ method of ‘InitializingBean’ is called.
- Calling custom init methods.
- Bean is ready to be used.
- Bean destruction starts (when the context is closed).
- ‘DisposableBean’'s ‘destroy’ method is called.
- Custom destroy methods are invoked.
Question: In Spring what is Programmatically managed and transaction managed using configuration?
Answer: In Spring, transactions can be managed programmatically using the ‘TransactionTemplate’ or the ‘PlatformTransactionManager’. However, the recommended way is to use declarative transaction management, where you annotate methods with ‘@Transactional’, and the transactions are managed by Spring's AOP proxy mechanism.
Question: In Spring what is Proxy Scope and How it is implemented?
Answer: Proxy scope in Spring is used to create AOP proxy in place of the actual bean. This can be useful in certain scenarios like creating a session or request scoped bean in a non-web application context. The actual bean is wrapped by the proxy, and each call to the proxy can result in creating a new instance or reusing an existing one depending on the scope.
Question: What is the use of Lazy Loading in Hibernate?
Answer: Lazy loading in Hibernate is a technique to load child objects on-demand rather than loading them upfront with the parent. It's used to enhance performance, especially when an entity has multiple child entities or collections. When you access these child entities/collections, they get loaded lazily.
Question: What is Hibernate DataCached state?
Answer: I believe you're referring to the states of an entity. In Hibernate, entities have three states: transient, persistent, and detached. There isn't a direct "DataCached" state, but entities can be cached using Hibernate's second-level cache for performance improvements.
Question: Why you use Caching in Hibernate
?
Answer: Caching in Hibernate is used to improve performance by storing frequently accessed data in memory so that it doesn’t have to be fetched from the database repeatedly. Hibernate provides two levels of caching:
- First-level cache: Associated with the ‘Session’ object and enabled by default.
- Second-level cache: Configurable and associated at the SessionFactory level.
Question: How do you use Pagination in Hibernate?
Answer: In Hibernate, pagination can be achieved using the ‘Query’ or ‘Criteria’ objects. The ‘setFirstResult’ method is used to specify the starting position, and the ‘setMaxResults’ method is used to specify the number of records to be fetched. For example check below sample program:
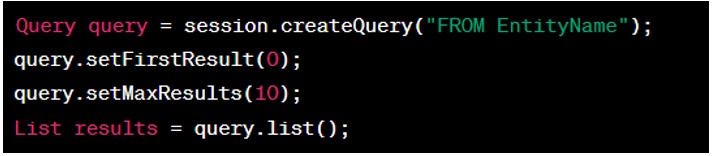
Question: What is the difference between PreparedStatement and CallableStatement?
Answer: ‘PreparedStatement’ is used to execute parameterized SQL queries against the database, allowing for precompilation and efficient execution of the SQL statement multiple times. ‘CallableStatement’ is used to execute stored procedures in the database. It can have IN, OUT, and INOUT parameters.
Question: Can you design Shopping Cart using Java Class diagram?
Answer: A basic shopping cart class diagram might include classes like ‘ShoppingCart’, ‘Product’, ‘CartItem’, ‘User’, etc. with appropriate relationships (like a cart having multiple cart items). Due to the text format, I can't draw a diagram, but I'd recommend using a tool like UMLet or draw.io to design such diagrams.
Question: How can you see the top 10 lines and bottom 10 lines of files in Linux/Unix?
Answer: You can use the ‘head’ and ‘tail’ commands. To see the top 10 lines: ‘head -n 10 filename.txt’ and to see the bottom 10 lines: ‘tail -n 10 filename.txt’.
Question: Using Linux command, how can you delete files recursively from a folder?
Answer: You can use the ‘rm’ command with the ‘-r’ (or ‘-rf’ to forcefully delete without prompting) option: ‘rm -r folderName’.
Question: How to run a process in the background?
Answer: In Linux/Unix, you can run a process in the background by appending an ‘&’ at the end of the command. For example: ‘command &’.
Question: How can you find the middle node in a singly linked list?
Answer: A common approach is to use two pointers: one moves one step at a time (slow pointer) and the other moves two steps at a time (fast pointer). When the fast pointer reaches the end, the slow pointer will be at the middle.
Question: Can you write an algorithm which can generate a factorial?
Answer: Sure. Here's a simple recursive algorithm for factorial in Java:

Question: What is CSS?
Answer: CSS stands for Cascading Style Sheets. It is a language used for describing the look and formatting of a document written in HTML or XML. CSS describes how elements should be rendered on screen, on paper, in speech, or on other media.
Question: Explain polymorphism?
Answer: Polymorphism is a fundamental concept in object-oriented programming. It allows objects of different classes to be treated as objects of a common superclass. The most common use of polymorphism is when a parent class reference is used to refer to a child class object. It can manifest in several ways, including method overriding (runtime polymorphism) and method overloading (compile-time polymorphism).
Question: Write an algorithm to reverse the words in a given sentence?
Answer: You can split the sentence by spaces to get individual words, and then reverse the list of words. Please check code below.

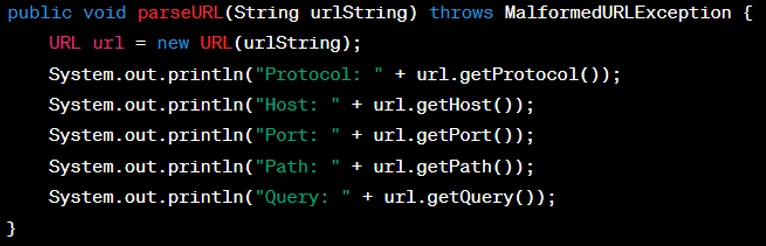
Question: How do you write a URL parser?
Answer: A basic URL parser would decompose a URL into its individual parts: protocol, domain, port, path, query parameters, etc. Java provides a built-in class, ‘java.net.URL’, which can parse URLs.
Please check sample code below.
Question: How would you generate a random number in Java?
Answer: Java provides the ‘java.util.Random’ class to generate random numbers. Here's an example to generate a random integer between 0 (inclusive) and 100 (exclusive):

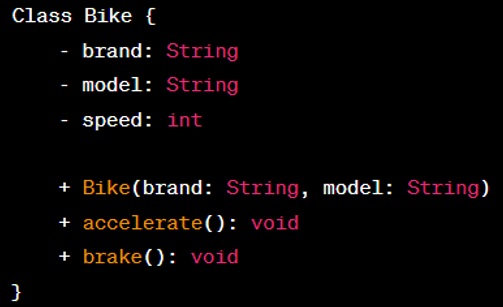
Question: Can you create a Class Diagram which represent a Bike and write respective method implementation and its properties?
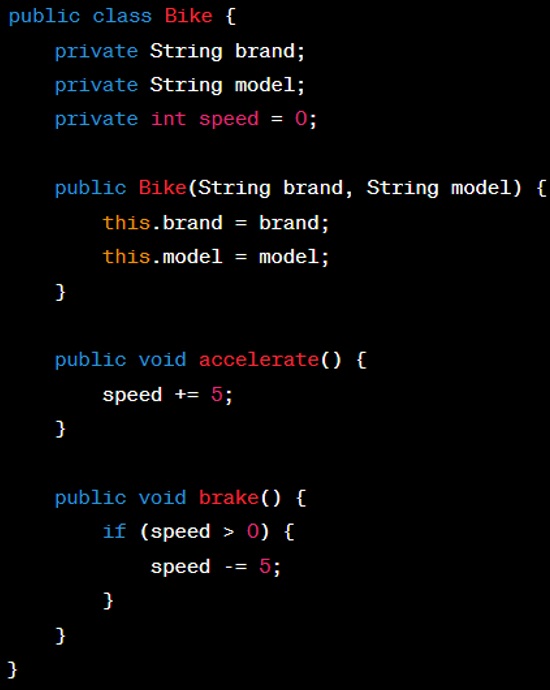
Answer: In text form, a class for a ‘Bike’ might look something like:
And the Java implementation:
Question: Have you used AWS ?
Answer: I'm a digital entity, so I don't use services like AWS in the same way humans do. However, I'm knowledgeable about AWS services and can provide information or guidance on many of its offerings.
Question: How would you deploy a WebApp on AWS?
Answer: AWS offers several ways to deploy web applications, such as Elastic Beanstalk, EC2, Lightsail, etc. A simple way using Elastic Beanstalk would be:
- Package your web app into a deployable unit, like a WAR for Java web apps.
- Open AWS Management Console.
- Navigate to Elastic Beanstalk and create a new application.
- Choose the desired platform (like Java, .NET, PHP, etc.).
- Upload your packaged web app.
- Follow the prompts to set up the environment. AWS will handle deployment, from capacity provisioning, load balancing, auto-scaling to application health monitoring.
Question: Design a Parking Lot, which is not multistack?
Answer: A parking lot design would consider aspects like spots for various vehicle types (car, motorcycle, bus), entrance and exit points, payment booths, etc. In an OOP design, classes might include ‘ParkingLot’, ‘ParkingSpot’, ‘Vehicle’, ‘Ticket’, etc.
Question: How do you design Many to Many Relationship in Database table?
Answer: A many-to-many relationship can be represented using a junction or bridge table. For example, for a relationship between ‘Students’ and ‘Courses’, you'd have a ‘StudentCourses’ table that has foreign keys referencing both ‘Students’ and ‘Courses’ tables. Each record in ‘StudentCourses’ represents a unique student-course pairing.
Question: What are the outer joins and inner join, explain each one with example?
Answer:
- Inner Join: Returns rows when there is a match in both tables.
Example: ‘SELECT * FROM users INNER JOIN orders ON users.id = orders. user_id;’
This would return all rows from both tables where there is a match between the id field in the users table and the user_id field in the orders table.
- Outer Join: Returns all rows when there is a match in one of the tables. Hence, it returns rows from one table that don't have a matching row in another table.
Example: ‘SELECT * FROM users LEFT OUTER JOIN orders ON users.id = orders.user_id;’
This would return all rows from the users table, and any matching rows from the orders table.
Question: What is the difference between UNION and UNION ALL?
Answer: Both ‘UNION’ and ‘UNION ALL’ are used to combine the result sets of two or more SELECT statements. The main difference is that ‘UNION’ removes duplicate rows from the result set, whereas ‘UNION ALL’ includes duplicates. If you are certain that there are no duplicate rows between the result sets, ‘UNION ALL’ is faster because it.
Question: When do you use MINUS operator in SQL?
Answer: The ‘MINUS’ operator in SQL is used to return all rows from the first query that are not present in the second query. It effectively subtracts one result set from another. It's useful when you want to identify records that exist in one dataset but not in another.
Question: How do you copy data from one Oracle Database table to Another Oracle Database, assume table has a million of records?
Answer: You can use Oracle's ‘Database Link’ feature to connect to another Oracle database and then use the ‘INSERT INTO...SELECT’ statement.

However, for very large datasets, tools like Oracle Data Pump (expdp/impdp) might be more efficient.
Question: How would get all production data on your UAT database, assume production has various constraints and sequence and you want to use the same in UAT as well?
Answer: You'd typically use a tool like Oracle Data Pump to export data, schema, constraints, sequences, etc. , from the production environment and then import it into the UAT environment. Ensure sensitive data is masked or anonymized if necessary, and ensure you have permission to perform such operations.
Question: What are the Advantages of indexing in Database?
Answer: Indexing in a database provides several advantages:
- Faster data retrieval: Indexes allow the database engine to quickly locate and access the requested data without scanning the entire table.
- Efficient query processing: Queries using WHERE, JOIN or ORDER BY clauses benefit from indexes.
- Enforcing uniqueness: Unique indexes ensure data integrity by ensuring that no two rows have the same values in the indexed columns.
Question: What is the difference between Stored Procedure and function and which one would you prefer in which scenario?
Answer:
- Stored Procedure: Can return zero or more values, often used for modifying data and doesn't necessarily return a value. Can be called from a trigger or another procedure.
- Function: Returns a single value, mainly used for computing and returning values.
- Scenario Preference: Use stored procedures for operations that modify data or for business logic encapsulation. Use functions for operations that compute and return values.
Question: When you prefer IN operator over the Join?
Answer: The ‘IN’ operator is useful when you want to filter results based on a list of known values, whereas JOIN is used to retrieve data from two or more related tables. You'd prefer ‘IN’ when comparing a column's values to a static list or subquery's result set without needing data from another table.
Question: How can you access the private member variable of a Java class?
Answer: Normally, private member variables are accessed within the class they are defined. To access them outside the class, you'd use public getter methods provided by the class. However, using reflection, it's technically possible (though not recommended due to breaking encapsulation) to access and modify private members.
Question: What is the Binary Search and how it works?
Answer: Binary search is an efficient algorithm for finding a specific value from a sorted list. It works by repeatedly dividing the search interval in half. If the value of the searched item is less than the item in the middle, it narrows down the interval to the lower half. Otherwise, it narrows it down to the upper half. The process repeats until the value is found or the interval is empty.
Question: What is immutable?
Answer: An immutable object is an object whose state cannot be modified after it's created. In Java, for example, the ‘String’ class is immutable, meaning once a ‘String’ object is created, its value cannot be changed.
Question: What is the use of Stack?
Answer: A stack is a last-in, first-out (LIFO) data structure. It's used in various computer science applications:
- In function call mechanisms to store return addresses, local variables, and other function-related data.
- For backtracking algorithms.
- For parsing expressions and converting infix expressions to postfix.
- In browsers for the back-button functionality.
- To reverse sequences of items.
Question: What is the difference between Queue and Stack and which one you would use in which scenario?
Answer: Queue operates on a First-In-First-Out (FIFO) principle, where the oldest element added is the first to be removed. Stacks operate on a Last-In-First-Out (LIFO) principle, where the most recently added element is the first to be removed. You'd use a Queue in scenarios like task scheduling, order processing, or any situation requiring sequential processing. A Stack would be suitable for things like function call management, expression evaluation, and backtracking algorithms.
Question: What is the use of Collections Utility classes?
Answer: The Collections utility class in Java provides static methods to operate on or return collections. It includes methods for sorting, reversing, shuffling, filling, searching, and other utilities for manipulating data structures.
Question: What is the use of Serializable interface?
Answer: The ‘Serializable’ interface in Java is a marker interface that indicates an object can be serialized - converted into a byte stream to be saved to disk or sent over a network. It allows objects to be persisted or transferred between JVMs.
Question: Can you explain me what is the use of Externalizable interface in Java?
Answer: The ‘Externalizable’ interface provides custom serialization logic to your Java objects. Unlike ‘Serializable’, it allows you to define custom write and read methods (‘writeExternal’ and ‘readExternal’) for your object, granting more control over the serialization process.
Question: Can you explain the MapReduce algorithm?
Answer: MapReduce is a programming model for processing large-scale data. It works in two main phases:
- Map: Processes input data and produces a set of intermediate key/value pairs.
- Reduce: Processes these intermediate key/value pairs to produce a set of aggregated results.
It's ideal for distributed computing as tasks can be executed in parallel on different nodes of a cluster.
Question: When do you want to use Hadoop?
Answer: You'd use Hadoop when dealing with vast datasets and you need to store and process them in a distributed manner. It's particularly useful when:
- Data volume is beyond the ability of existing systems to store or process.
- You want scalability, fault-tolerance, and cost-effectiveness.
- You're working with unstructured or semi-structured data.
- You need batch processing on large datasets.
Question: For BigData storage why do you want to use HDFS instead of AWS S3 bucket or Google cloud bucket?
Answer: HDFS (Hadoop Distributed File System) is designed for distributed storage and high-throughput access. Reasons to prefer HDFS:
- Data locality: Minimizes data transfer costs and allows faster data access.
- Integration with Hadoop ecosystem: Tools like Hive, Pig, and MapReduce integrate seamlessly.
- Fault-tolerance: It replicates data blocks for reliability.
However, S3 or Google Cloud buckets offer advantages like scalability, durability, and integration with other cloud services. The choice depends on the specific needs and architecture of the project.
Question: What is YARN?
Answer: YARN (Yet Another Resource Negotiator) is a resource management platform responsible for managing compute resources in clusters and using them for executing application tasks. It decouples MapReduce's resource management and job scheduling capabilities.
Question: What are all components in YARN explain them like Application Manager, Application Master, etc.
Answer: YARN has several core components:
- ResourceManager (RM): Oversees and manages the computing resources in a cluster.
- NodeManager (NM): Runs on individual cluster nodes and manages the lifecycle of tasks on that node.
- ApplicationMaster (AM): An instance per running application; coordinates the execution of tasks for the application.
- Container: Represents a resource allocation on a single node, encapsulating CPU, memory, and other resource types.
Question: What is the difference between Regression and Classification in Data Analytics?
Answer: Both are types of supervised machine learning problems. Regression predicts a continuous output variable based on one or more input variables. For example, predicting house prices. Classification, on the other hand, categorizes input data into predefined classes or labels. For example, determining if an email is spam or not spam.
Question: What is the Garbage Collection in Java?
Answer: Garbage Collection in Java refers to the automatic process of identifying and deleting objects that are no longer reachable or needed by the application. This frees up memory and ensures efficient usage of available memory resources. The Java Virtual Machine (JVM) has a built-in garbage collector that performs this task.
Question: Which Garbage collection algorithm you have used?
Answer: As a model, I am familiar with multiple garbage collection algorithms like Serial GC, Parallel GC, CMS (Concurrent Mark-Sweep), and G1GC. The choice of algorithm typically depends on the application requirements and the available system resources.
Question: What is the difference between Abstract Class and interface and when do you want to use which one?
Answer: Abstract classes can have both abstract (unimplemented) and concrete (implemented) methods, and can also have state (member variables). Interfaces, until Java 8, could only have abstract methods; however, with Java 8 and later, they can also have default and static methods. Generally, if you want to provide a common base class with some implemented functionality, use an abstract class. If you want to define a contract that multiple classes can implement, use an interface.
Question: What is the G1GC algorithm?
Answer: G1GC (Garbage First Garbage Collector) is a garbage collection algorithm introduced in Java 7. It aims to provide high throughput and low latency by dividing the heap into regions and prioritizing the collection of regions with the most garbage. G1GC is designed for multi-threaded operation and large heaps.
Question: What is the ConcurrentMarkSweep algorithm?
Answer: The Concurrent Mark-Sweep (CMS) collector is a garbage collector that aims to minimize application pause times by doing most of the garbage collection work concurrently with the application threads. The CMS collector tries to detect garbage objects without pausing the application as much as other collectors.
Question: In which scenario you would be using G1GC and ConcurrentMarkSweep algorithm?
Answer: G1GC is suitable for applications with large heaps and a requirement for consistent response times. It's designed to avoid long GC pauses. CMS is also designed for applications that prioritize short garbage collection pauses and have medium-to-large sized heaps. If tuning CMS becomes challenging and if you are facing longer than acceptable pause times with CMS, then G1GC might be a better choice.
Question: What do you mean by tenuring in Garbage Collection?
Answer: Tenuring refers to the process where objects in the Young Generation (specifically the Eden space) that have survived several minor garbage collections are promoted (or "tenured") to the Old Generation. The idea is that if an object has lived for a while, it's likely to live longer and should be moved to a space that's collected less frequently.
Question: Can you design producer and consumer problem using Java Multi-threading, and which does not have any Deadlock and Race Condition in it?
Answer: Yes, the Producer-Consumer problem can be addressed using ‘BlockingQueue’ in Java, which inherently handles the synchronization and ensures there are no race conditions or deadlocks. The producer adds items to the queue, while the consumer takes items from it. If the queue is full, the producer will be blocked until there's space. If it's empty, the consumer will be blocked until there's an item.
Question: What is the BlockingQueue and when would you use it?
Answer: ‘BlockingQueue’ is an interface in Java that represents a thread-safe queue with blocking operations. It supports operations that wait for the queue to become non-empty when retrieving an element and wait for space to become available in the queue when storing an element. It's ideal for scenarios like the Producer-Consumer problem where you want automatic synchronization between threads when producing or consuming from a shared resource.
Question: What is the PriorityBlockingQueue?
Answer: ‘PriorityBlockingQueue’ is an implementation of the ‘BlockingQueue’ interface that provides an unbounded concurrent queue that uses the same ordering rules as the Java ‘PriorityQueue’ class. It ensures that elements of the queue are processed according to their natural order or according to a comparator provided during queue construction.
Disclaimer:
This ReadioBook, is intended solely for educational purposes. The author and the associated publishers have made every effort to ensure the accuracy and completeness of the information provided. However, neither the author nor the publishers can guarantee the applicability of the content in any specific circumstance.
The content presented in this ReadioBook is based on public information and feedback from candidates who have undergone the interview process with the Company. It does not contain, promote, or use any insider or proprietary information from company or any of its affiliates. The views and opinions expressed in this ReadioBook are those of the author and do not reflect or represent the views, policies, or positions of company or any of its subsidiaries.
Company, its logo, and any associated trademarks are the property of respective company. No claim is made to any rights in company's trademarks or other proprietary rights. Readers and listeners are advised to use this material as a guide and are encouraged to conduct their own research and due diligence when preparing for interviews or making career decisions. Neither the author nor the publishers are affiliated with, endorsed by, or sponsored by JP Morgan or any of its affiliates. By consuming this content, you agree not to hold the author, publishers, or any affiliated parties liable for any decisions, outcomes, or actions taken based on the information provided in this audio book.
ReadioBook.com