
Note: For all 7 chapters, please refer to the navigation section above.
Chapter 1: Big Data Developer First Technical Round.
Introduction: The evolution of Big Data has brought about a paradigm shift in the way organizations handle information. It has not only expanded the horizons of data analytics but has also opened up new pathways for technological advancements and innovative problem-solving approaches. Entering the heart of this data revolution is the role of a Big Data Developer – a position that amalgamates the artistry of software development with the science of data analytics.

Job Title: Big Data Developer.
Location: Chennai, Bengaluru, Mumbai, New York, London.
Job description & Responsibilities.
- Over 2+ years of experience in Java, Bigdata technologies
- Knowledge of Spark, Hadoop, Hive, python, kafka, C I and C D tools, Configuration and Release Management, deployments and troubleshooting environments.
- Good understanding of the Big Data architecture and its components
- Expertise in scripting languages like shell scripts, Python.
- Understanding of scheduling tools is good to have.
- Good understanding of ETL and DWH concepts.
- Experience in Agile methodolgies.
- Excellent communication skills, analytical ability, agility and ownership around tasks.
- You will understand requirements, create and review designs, validate the architecture and ensure high levels of service offerings to clients in the technology domain.
- You will participate in project estimation, provide inputs for solution delivery, conduct technical risk planning, perform code reviews and unit test plan reviews.
- You will lead and guide your teams towards developing optimized high quality code deliverables, continual knowledge management and adherence to the organizational guidelines and processes.
- You would be a key contributor to building efficient programs/ systems and if you think you fit right in to help our clients navigate their next in their digital transformation.
- Candidates having hands on experience Bigdata technology.
- Should have worked on Java in the past.
- Hands on Big Data and experience on Datalake projects.
Preferred & primary skills:
- Bigdata and Python.
- Opensource and Apache Kafka.
- Bigdata and Hadoop.
- Bigdata and Pyspark.
- Bigdata and Spark.
- Bigdata and Scala.
- Bigdata and Apache NiFi.
- Bigdata and Apache Flink.
David: Can you tell me about your experience with Java and how you've applied it in the context of Big Data technologies?

Gayathri: Sure, I have over two years of experience in Java, particularly in implementing backend services. I've utilized Java for creating Hadoop MapReduce jobs and managing data ingestion into HDFS. Java's robustness also came in handy when I was working on Spark applications for data processing.
David: What is your level of expertise with Spark and Hadoop, and can you provide an example of a project you worked on using these technologies?
Gayathri: I would rate my expertise in Spark and Hadoop as intermediate to advanced. For instance, on a recent project, I used Spark to perform data transformations and aggregations on a multi-terabyte dataset, which was then stored and managed in Hadoop's distributed file system.
David: How proficient are you with Hive, and have you used it in conjunction with Python for data querying and manipulation?
Gayathri: I have a good grasp of Hive. I've often used it with Python to write scripts for automating data queries and manipulations. Hive's SQL-like interface made it easier to perform data analytics on top of Hadoop ecosystems.
David: Can you discuss your experience with Kafka, particularly in data streaming and processing scenarios?
Gayathri: Yes, Kafka has been integral in most of the real-time data processing solutions I've worked on. I've used Kafka for building scalable and fault-tolerant streaming pipelines to process data in real-time, ensuring data is efficiently moved between different parts of the application.
David: Describe your familiarity with CI/CD tools and how you've implemented them in your Big Data projects.
Gayathri: I've used CI/CD tools such as Jenkins and GitLab CI for automating the build, test, and deployment phases of Big Data applications, which significantly improved the code quality and deployment frequency.
David: How would you explain the Big Data architecture to a layperson?
Gayathri: Big Data architecture is like a complex factory where raw data is the input. This factory has various specialized machines (like Hadoop, Spark, Kafka) that process and refine the data, turning it into valuable information that businesses can use to make informed decisions.
David: What scripting languages are you comfortable with, and how do they complement your Big Data skills?
Gayathri: I am comfortable with shell scripting and Python, which complement my Big Data skills by automating routine data processing tasks, writing ETL jobs, and managing data pipelines effectively.
David: How important is understanding scheduling tools in Big Data projects, and do you have any experience with them?
Gayathri: Scheduling tools like Airflow or Oozie are important for orchestrating complex workflows. I have used Airflow to schedule and monitor pipelines of jobs that involve data extraction, transformation, and loading.
David: Can you elaborate on your understanding of ETL and DWH concepts in the context of Big Data?

Gayathri: ETL stands for Extract, Transform, Load, and it’s the process of moving data from various sources, transforming it into a format that can be analyzed, and loading it into a Data Warehouse (DWH) for analysis. In Big Data, these processes happen at a much larger scale and often involve distributed systems.
David: How has your experience with Agile methodologies enhanced your work in Big Data projects?
Gayathri: Agile methodologies have enabled me to adapt quickly to changes, work collaboratively with cross-functional teams, and deliver incremental value through sprints, which is especially important in the fast-paced Big Data environment.
David: Communication skills are crucial in any role. Can you give an example of how your communication skills have been important in your Big Data work?
Gayathri: Effective communication was crucial when I was leading a team to implement a Big Data solution. I had to ensure that the requirements were clearly understood and that the technical aspects were translated into business benefits for stakeholders.
David: Describe a situation where you had to understand requirements and translate them into a technical design for a Big Data solution.
Gayathri: On a recent project, I gathered requirements from business users to understand their data analysis needs. I translated these requirements into a technical design by choosing the appropriate Big Data technologies, like Spark for processing and Hive for querying.
David: Can you talk about your role in project estimation and solution delivery in the Big Data domain?
Gayathri: I have been involved in project estimation by assessing the scope and complexity of data tasks. I've contributed to solution delivery by designing and implementing scalable Big Data solutions that meet the project's estimated guidelines.
David: How do you approach technical risk planning in your projects?
Gayathri: Technical risk planning involves identifying potential issues that might arise during the project. I mitigate these by conducting thorough reviews, planning for backups, and having contingency plans, especially when dealing with large data volumes and complex transformations.
David: What is your approach to performing code reviews and unit test plan reviews?
Gayathri: My approach to code reviews is methodical, ensuring that the code is clean, well-documented, and follows best practices. For unit test plans, I review to confirm that they cover all the possible scenarios and edge cases to ensure robustness.
David: How do you lead and guide teams towards developing optimized high-quality code deliverables in Big Data projects?
Gayathri: I lead by example, follow coding standards, and encourage regular code reviews. I also facilitate knowledge-sharing sessions to keep the team updated on the latest Big Data best practices and technologies.
David: What makes you a key contributor in building efficient programs/systems in the Big Data realm?
Gayathri: My commitment to writing clean, maintainable code and my continuous learning attitude make me a key contributor. I stay abreast of the latest Big Data trends and apply them to build efficient and scalable systems.
David: Describe your hands-on experience with Big Data technologies and any Datalake projects you've worked on.
Gayathri: I've worked hands-on with Big Data technologies in several projects, setting up data lakes using Hadoop and processing data using Spark. These data lakes acted as centralized repositories where data could be stored in its raw format and then processed as needed.
David: How have your previous experiences with Java shaped your current expertise in Big Data?
Gayathri: My foundational knowledge in Java has been instrumental in understanding and implementing Big Data technologies, as many of them, like Hadoop and Spark, are Java-based. It has made it easier for me to write efficient data processing jobs.
David: Can you share your experience with Python in Big Data, specifically any open-source projects or Kafka integrations?
Gayathri: I have utilized Python extensively in Big Data, especially with Kafka for creating consumer and producer scripts that handle streaming data. I’ve also contributed to some open-source projects by writing Python scripts that enhance data processing capabilities.
David: Can you walk me through the process of how you've implemented a data ingestion pipeline using Kafka?
Gayathri: Certainly. In my last project, I implemented a Kafka-based ingestion pipeline that consumed data from various sources in real-time. I set up Kafka producers that published data to Kafka topics. The data was then consumed by Spark Streaming jobs that performed initial transformations and pushed the data into HDFS for further processing.
David: What strategies do you employ to handle large-scale data transformations in Spark?

Gayathri: For large-scale data transformations in Spark, I utilize its in-memory computing capabilities and lazy evaluation. I also optimize transformations by choosing the right operators, like map and reduce, and persisting intermediate RDDs when necessary to minimize recomputation.
David: Can you discuss a time when you had to optimize a Hadoop job that was running inefficiently?
Gayathri: In one instance, a MapReduce job was running slowly due to data skew. I addressed this by customizing the partitioner to distribute the workload evenly across all the reducers. Additionally, I optimized the shuffle phase by tuning the configuration parameters like ‘mapreduce.job.reduces’ and ‘io.
sort.mb’.
David: How do you ensure data quality when using Hive for ETL processes?
Gayathri: Ensuring data quality in Hive involves implementing checks during the ETL process. I write HiveQL scripts with validation checks, use assertions for data types, and ensure referential integrity. For data deduplication, I employ windowing functions to filter out duplicates.
David: Describe your experience with CI/CD in the context of deploying Big Data applications.
Gayathri: My CI/CD experience involves using Jenkins to automate the deployment of Big Data applications. I've set up pipelines that run unit tests, perform code analysis, build artifacts, and deploy them to a staging environment. This ensures that the code is tested and deployed consistently.
David: What is your approach to troubleshooting environment issues in Big Data ecosystems?
Gayathri: Troubleshooting in Big Data ecosystems involves identifying the component causing the issue, whether it’s within Hadoop, Spark, or the data pipeline. I analyze log files, check system resources, and isolate the problem area, then apply a targeted solution to resolve the issue.
David: How do you manage stateful processing in Spark Streaming applications?
Gayathri: Managing state in Spark Streaming is crucial for applications that require tracking across batches. I use updateStateByKey or mapWithState APIs to maintain state. For fault tolerance, I ensure that the state is checkpointed at regular intervals.
David: Can you give an example of a time you used Python to automate a task in a Big Data context?
Gayathri: I used Python to automate the monitoring of a Hadoop cluster. The script collected metrics from the NameNode and ResourceManager APIs and sent alerts if certain thresholds were exceeded, such as disk space utilization or node failures, to prevent potential issues.
David: Explain how you've implemented ETL workflows in a DWH setup within a Big Data environment.
Gayathri: I implemented ETL workflows by extracting data from various sources, including logs, databases, and APIs. I used Apache NiFi for data flow automation and transformation before loading the data into a Hive Data Warehouse. The workflows were designed to be scalable and repeatable for daily batch processes.
David: How do you balance the need for immediate insights with the requirements of complex data transformations in an Agile Big Data project?
Gayathri: In an Agile environment, I prioritize building a minimum viable product (MVP) that provides immediate insights. Complex data transformations are then iteratively added and refined in subsequent sprints, balancing the need for quick wins with the evolution of the data pipeline.
David: Discuss how you've used shell scripts in managing Big Data applications.
Gayathri: I've used shell scripts for various tasks, such as automating the start-up and shut-down of Hadoop clusters, deploying Spark jobs, and scheduling backups. The scripts were also used for health checks and to send notifications in case of failures.
David: Can you talk about a specific project where your analytical abilities were crucial in delivering a Big Data solution?
Gayathri: In a project aimed at predicting customer churn, my analytical abilities helped in processing large datasets to identify patterns. I used Spark MLlib to build predictive models and analyzed the results to refine the model for better accuracy.
David: How do you ensure that your Big Data solutions adhere to both technical and business requirements?

Gayathri: By maintaining close communication with business stakeholders and translating their requirements into technical specifications. I ensure the solutions I design are aligned with business goals and the technical architecture is robust enough to support those objectives.
David: Could you describe your role in the architectural validation of Big Data solutions?
Gayathri: As part of architectural validation, I review the proposed solutions against established architectural principles, such as scalability, fault tolerance, and data consistency. I also perform proof of concepts to validate the architecture before full-scale implementation.
David: How do you estimate the effort required for Big Data projects during the planning phase?
Gayathri: Estimating effort requires understanding the complexity of the data, the transformations needed, and the end goals. I break down the project into smaller tasks, estimate each individually, and then consolidate to get an overall estimate, adding buffers for unforeseen challenges.
David: Discuss your experience with code reviews and ensuring high-quality code in Big Data applications.
Gayathri: During code reviews, I focus on the efficiency of data processing, the scalability of the code, and adherence to best practices. I use tools like SonarQube for static code analysis and insist on comprehensive unit tests to ensure code quality.
David: How do you manage knowledge transfer within your Big Data team?
Gayathri: I encourage my team to document all processes and solutions. We also conduct regular brown-bag sessions where team members present on topics they've worked on or new technologies they've explored, ensuring continuous knowledge transfer.
David: What methods do you use to guide your teams in developing optimized code for Big Data applications?
Gayathri: I guide my teams by establishing coding standards, conducting performance benchmarking sessions, and regular peer code reviews. We also focus on continuous refactoring and performance tuning of the Big Data applications.
David: How do you keep up with the evolving Big Data landscape to be a key contributor in your field?
Gayathri: I keep myself updated through online courses, attending webinars, participating in forums, and contributing to open-source projects. This helps me stay abreast of the latest trends and best practices in Big Data.
David: Explain how your previous Java experience benefits you in your current role as a Big Data Developer.
Gayathri: My Java experience is beneficial for understanding the internals of Big Data frameworks like Hadoop and Spark, which are largely written in Java. It allows me to write optimized code and debug issues effectively.
David: Can you detail your experience with Datalake projects and the role of Big Data technologies in them?
Gayathri: In my experience with Datalake projects, Big Data technologies like Hadoop were central to storing and processing diverse datasets in their native format. I used tools like Spark for processing the data and integrated various data sources into the Datalake for a unified view.
David: Could you describe a situation where you had to optimize a Spark job? What were the steps you took and the outcome?

Gayathri: In a past project, we had a Spark job that was taking too long to complete. I started by analyzing the Spark UI to understand the job stages and task execution times. I noticed that the job was reading a large number of small files, causing excessive overhead. I consolidated the input files into fewer larger files, repartitioned the data to ensure even distribution, and cached the RDDs used in multiple actions.
The result was a reduction in the job completion time by about 40%.
David: What's your approach to debugging a data pipeline that has failed due to an unknown error?
Gayathri: When faced with an unknown error, my approach is systematic. I begin by checking the logs to pinpoint where the failure occurred. If the logs are not clear, I replicate the issue in a lower environment with debug-level logging enabled. I also examine the data input to the failing component for anomalies.
Once I identify the issue, I address it, test the fix, and document the resolution process for future reference.
David: How do you ensure the efficiency of a Hive query that handles large datasets?
Gayathri: To ensure Hive query efficiency, I apply several optimizations. I start by structuring the data in a columnar format like Parquet or ORC to reduce I/O. Then, I use partitioning and bucketing to minimize the data scanned by each query. I also make sure to collect table statistics for the cost-based optimizer to work effectively.
If necessary, I'll use materialized views for common subqueries.
David: In Kafka, how would you handle data rebalancing caused by a broker failure?
Gayathri: Kafka's consumer groups handle rebalancing automatically. However, to manage this effectively, I ensure that the message consumption is idempotent and can handle duplicates. I also set appropriate session timeout and rebalance listener configurations to manage consumer recovery and minimize processing delays.
David: Can you discuss a time when you had to deal with a memory leak in a Java-based Big Data application?
Gayathri: I encountered a memory leak in a Java-based application where the heap memory was getting exhausted. Using profiling tools like VisualVM, I identified that certain objects were not getting garbage collected. It turned out to be a static collection that was accumulating objects without ever being cleared.
I refactored the code to ensure the collection was periodically cleared and properly scoped.
David: Explain how you would implement idempotent writes in a distributed Big Data system.
Gayathri: To implement idempotent writes, I make sure that the operation to write data can be repeated without changing the result beyond the initial application. This is typically achieved by using unique identifiers for data records and checks to prevent duplicate entries. In the context of a distributed system like Hadoop, this could involve leveraging HDFS's file atomicity properties.
David: How would you perform a root cause analysis for a slow-running ETL process?
Gayathri: For a slow-running ETL process, I would perform a root cause analysis by first examining the ETL pipeline stages and identifying the bottlenecks using logging and monitoring tools. I would check the database execution plans for the ETL queries, the data models, and the infrastructure metrics like CPU, memory, and disk I/O.
Based on the findings, I would optimize the queries, redesign the data model, or scale the infrastructure as needed.
David: What considerations do you take into account when scaling out a Hadoop cluster?
Gayathri: When scaling out a Hadoop cluster, I consider factors like data volume growth, the processing power needed for current and future workloads, network topology, and the balance between compute and storage nodes. I ensure that the cluster is scaled horizontally to maintain fault tolerance and that the new nodes are properly configured and balanced with the existing ones.
David: Describe how you would use Python to manipulate data stored in HDFS.
Gayathri: To manipulate data in HDFS with Python, I would use libraries like PyArrow or HdfsCLI to interact with the HDFS API. I could write Python scripts to perform file operations like read, write, and delete. For data processing, I might use PySpark to leverage Spark's distributed processing capabilities with the ease of Python programming.
David: How do you implement monitoring in your Big Data applications, and which tools do you use?
Gayathri: For monitoring Big Data applications, I implement logging at various levels of the application and use tools like Elasticsearch, Logstash, and Kibana (ELK stack) for log aggregation and visualization. I also use application performance monitoring tools like Prometheus and Grafana to monitor the health and performance metrics of the applications.
David: Can you explain how you would secure sensitive data within a Big Data environment?
Gayathri: Securing sensitive data in a Big Data environment involves implementing encryption at rest and in transit, using secure authentication and authorization mechanisms, and applying fine-grained access controls. Tools like Apache Ranger and Knox can be used for access control, and Kerberos for authentication.
David: What's your experience with real-time data processing, and what technologies have you used?
Gayathri: I have experience with real-time data processing where I've used technologies like Apache Storm, Kafka Streams, and Spark Streaming. These technologies allow me to process data as it arrives, enabling near-real-time analytics and decision-making.
David: How do you manage and process time-series data in a Big Data context?
Gayathri: For time-series data, I ensure the database or datastore is optimized for time-based querying, often using a columnar storage format. If I'm using Hadoop, I might leverage HBase for its efficient read/write capabilities on time-series data. For processing, I would use Spark with window functions to aggregate and analyze the data over time intervals.
David: Can you talk about how you handle data partitioning and sharding in distributed databases?
Gayathri: In distributed databases, data partitioning and sharding are critical for performance and scalability. I determine the partitioning strategy based on the access patterns, such as range or hash-based partitioning. I ensure the data is evenly distributed to avoid hotspots and periodically monitor and rebalance the shards as needed.
David: Discuss how you would optimize a batch job that processes a day's worth of data every night.
Gayathri: To optimize a nightly batch job, I would first ensure that the job is only processing the new or changed data by implementing incremental loads. I would also optimize the job's execution plan, index the source data if possible, and use parallel processing. Additionally, I'd schedule the job during off-peak hours to minimize the impact on the production systems.
David: How do you ensure that your Spark jobs are fault-tolerant?
Gayathri: Spark's inherent fault tolerance is achieved through its use of RDDs, which are automatically rebuilt in case of node failure. To further ensure fault tolerance, I design jobs to be idempotent and use checkpointing and write-ahead logs when working with Spark Streaming.
David: Explain a scenario where you had to use machine learning algorithms in a Big Data project.
Gayathri: In a project focused on customer segmentation, I used machine learning algorithms to analyze customer data and identify distinct groups based on their purchasing behavior. Using Spark MLlib, I applied clustering algorithms like K-Means to process the large dataset and determine the customer segments.
David: How do you approach the challenge of integrating structured and unstructured data in a Big Data solution?
Gayathri: Integrating structured and unstructured data involves establishing a schema-on-read strategy where the data structure is inferred at the time of reading. I use tools like Apache NiFi for data flow management and Apache Hadoop for storing unstructured data in HDFS. Then, I employ Spark to process and unify the data into a structured format.
David: What methods do you use for Big Data backup and disaster recovery?
Gayathri: For Big Data backup and disaster recovery, I implement strategies such as data replication across multiple nodes and geographical locations, regular snapshots of the HDFS namespace, and using cloud storage solutions for off-site backups. I also establish a disaster recovery plan that includes processes for restoring data and applications quickly.
David: Can you describe how you've used Scala in the context of Big Data processing?
Gayathri: I've used Scala primarily with Apache Spark for Big Data processing due to its functional programming features and concise syntax. Scala allows me to write high-level code that is both expressive and efficient for Spark's distributed processing capabilities.
David: Given a dataset of sales transactions, how would you write a Spark job in Scala to find the total sales per day?
Gayathri: I would use the Spark DataFrame API in Scala to read the dataset into a DataFrame, then I would group the data by the 'date' column and sum the 'sales' column. The code would look something like this:

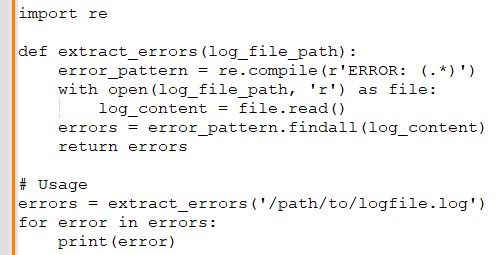
David: How would you implement a Python function to parse log files and return error messages?
Gayathri: I would use Python's regular expressions module to search for error patterns. Here's a simple function that might do the job:
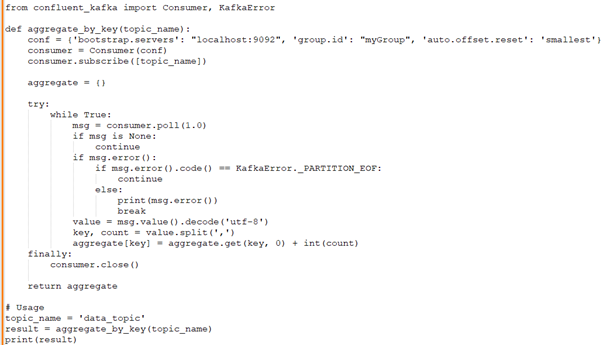
David: Suppose you have a stream of data coming in. How would you use Kafka and Python to write a consumer that aggregates this data by key?
Gayathri: I would use the ‘confluent_kafka’ Python library to write a Kafka consumer that subscribes to the topic and aggregates data. Here's a code snippet:
David: Write a Java method that takes an array of integers and returns the array sorted in descending order.
Gayathri: Here's a simple Java method that accomplishes this using the built-in sort function and a custom comparator:

David: How would you use a shell script to find and list all the files in a directory with a ".log" extension and that contain the word "error"?

Gayathri: I would use the ‘find’ and ‘grep’ commands in a shell script like so:

David: Can you write an SQL query to select all distinct customers who made purchases above $100 on a given day?
Gayathri: Sure, here's an example SQL query:

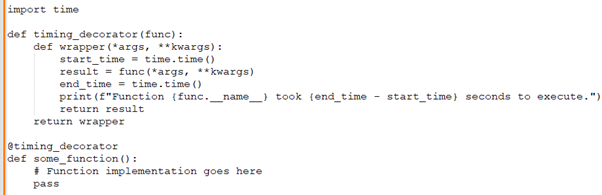
David: In Python, how would you write a decorator that times the execution of a function?
Gayathri: Here's a Python decorator that does just that:
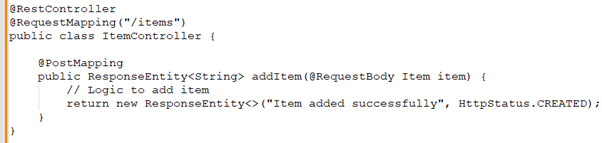
David: If you were to write a RESTful API using Java and the Spring Framework, how would you handle a POST request to add a new item?
Gayathri: I would use the ‘@RestController’ annotation and handle the POST request with the ‘@
PostMapping’ annotation. Here's a simple example:
David: Can you write a Scala function that takes a List of integers and returns the list without any duplicates?
Gayathri: Yes, in Scala, it's quite straightforward:

David: Using Apache NiFi, how would you design a flow that reads data from a REST API every hour and writes the results to HDFS?
Gayathri: In Apache NiFi, I would use ‘InvokeHTTP’ processor to call the REST API, followed by a ‘ConvertRecord’ processor to format the data if necessary, and then a ‘PutHDFS’ processor to write the results to HDFS. I would schedule the ‘InvokeHTTP’ processor to run every hour.
David: Describe a method in Python to connect to a MySQL database and execute a query that returns the number of records in a table.
Gayathri: You would use a connector like ‘mysql-connector-python’. Here's how you could write the method:

David: Imagine you have JSON data being streamed. How would you deserialize this data in Scala using a case class?
Gayathri: To deserialize JSON data into a case class in Scala, you can use libraries like play-json. Here's an example:

David: Write a function in Java that reverses an input string.
Gayathri: Here's a simple Java method for string reversal:

David: How would you write an R function that calculates the mean of a numeric vector, excluding any NA values?
Gayathri: In R, you can calculate the mean without NA values like this:

David: If you're given a large CSV file, how would you use Python's Pandas library to read and process this file in chunks?
Gayathri: You can use the ‘read_csv’ function with the ‘chunksize’ parameter:

David: Can you provide an example of a complex SQL query you've written that involves subqueries and joins?
Gayathri: Certainly, here's an example:


David: Congratulations, Gayathri, on successfully clearing the first round of the Big Data Developer interview! You demonstrated excellent technical knowledge and problem-solving skills. Now, I'd like to inform you that you've advanced to the next round of interviews.
Gayathri: Thanks David.

ReadioBook.com