
Chapter 2: API Architect, Developer and Manager Second Round Technical Interview.
Introduction: Welcome to Chapter Two of our in-depth exploration into the dynamic world of cloud infrastructure and Kubernetes orchestration. In this chapter, we'll be accompanying our candidate, Priyanka, as she engages in a rigorous discussion with the Associate Director of the Central IT Team. This team is at the forefront of our organization's cloud infrastructure management and deployment strategies.

Benjamin: Priyanka, let's begin with your methodology. Can you walk me through your process for designing a scalable API architecture?
Priyanka: Certainly, Benjamin. When designing a scalable API architecture, I start by identifying the core functionalities and the expected load. I advocate for stateless design and use RESTful principles to ensure scalability. Load balancers and horizontal scaling are key, and I often leverage cloud services' auto-scaling features.
I also implement caching strategies and rate limiting to manage the load effectively. The use of microservices allows for scaling individual components as needed without affecting the entire system.
Benjamin: Security is paramount. How do you approach security and authentication when architecting APIs?
Priyanka: Security is integrated from the outset. I use HTTPS to secure data in transit and employ OAuth 2.0 for secure, token-based user authentication. For service-to-service authentication, I use JWT tokens with robust signature algorithms. I also conduct regular security audits, implement API gateways for additional security layers like WAF, and follow the principle of least privilege when defining access controls.
Benjamin: What are your strategies for API versioning, and how do you handle deprecated features?
Priyanka: I follow semantic versioning principles. Major changes result in a version bump, and I maintain backward compatibility as much as possible. For deprecated features, I provide ample notice to consumers, document the alternatives, and maintain the deprecated version alongside the new version for a transition period.
Routes in my codebase include versioning so that they can coexist and are served correctly based on the request.
Benjamin: Given a scenario with a high volume of concurrent requests, how would you design an API to handle it?
Priyanka: For high concurrency, I design APIs to be asynchronous where possible, using non-blocking I/O. I'd also implement a robust caching mechanism, fine-tune the database for high read/write speeds, and use a message queue system to handle requests efficiently. Here's a snippet that outlines a non-blocking controller method:

Benjamin: When monitoring API performance, what metrics do you consider most important?
Priyanka: The key metrics include latency, error rate, and throughput. I also monitor the rate of traffic growth, response times for different endpoints, and system resource utilization to preemptively scale services before users experience degradation.
Benjamin: Can you describe a challenge you faced with API gateway management and how you resolved it?
Priyanka: I encountered a challenge with API rate limiting, where legitimate traffic spikes were being throttled. I resolved it by implementing a more sophisticated rate-limiting algorithm that could distinguish between normal traffic patterns and abuse, and by allowing bursts of traffic from known good actors.
Benjamin: How do you ensure that the APIs you design align with both current and future business needs?
Priyanka: I work closely with business analysts to understand the current and projected business needs. I design APIs with extensibility in mind, using a modular approach so that new features can be added as plug-and-play components without disrupting existing functionality.
Benjamin: Documentation is vital. What tools and techniques do you use for API documentation?
Priyanka: I use Swagger and OpenAPI specifications for documentation. These tools provide interactive documentation that can be used by both internal developers and external consumers. They allow for real-time testing of API endpoints, which is invaluable for understanding API behavior.
Benjamin: Explain how you design APIs for microservices architectures versus monolithic architectures.
Priyanka: In a microservices architecture, APIs are designed to be small and focused on a specific service or functionality. They are independently deployable, which allows for greater flexibility and scalability. In contrast, APIs in a monolithic architecture tend to be larger and are designed to handle multiple functionalities within a single, unified service.
Benjamin: Finally, how do you balance the trade-offs between API simplicity and feature richness?
Priyanka: I strive for minimalism in API design, exposing only what's necessary and keeping the usage intuitive. For feature richness, I use the expandability of the RESTful design, allowing clients to request additional, optional data when needed. This way, the core API remains simple for those who need less, while still supporting clients that require more complex interactions.
Benjamin: Error management is crucial for a good API. How do you handle it in APIs you develop?
Priyanka: I use a standardized error response structure across all APIs. Each error response includes a machine-readable code, human-readable message, and optionally, a detailed description or link to more information. In Spring Boot, I use `@ControllerAdvice` and `@ExceptionHandler` annotations for global error handling.
Here's an example:
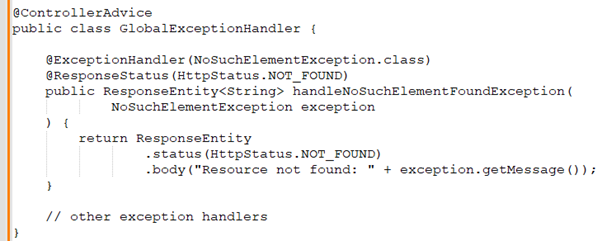
Benjamin: What frameworks or languages do you prefer for API development and why?
Priyanka: I prefer Spring Boot for API development due to its vast ecosystem, ease of use, and the ability to quickly set up robust, production-ready APIs. For languages, Java is my go-to for its strong typing, performance, and the vast array of available libraries and tools for development and testing.
Benjamin: Can you describe your experience with RESTful and GraphQL APIs? What are the pros and cons of each?
Priyanka: I've worked with both RESTful and GraphQL APIs. REST is great for standard CRUD operations and is supported by virtually all platforms. However, it can lead to over-fetching or under-fetching data. GraphQL addresses this with its query language, allowing clients to specify exactly what data they need, which can be more efficient.
The downside of GraphQL is its complexity; it requires a deeper understanding and has a steeper learning curve.
Benjamin: How do you ensure the security of the APIs you develop?
Priyanka: Security is ensured through several layers: HTTPS for encryption, using OAuth and JWT for authentication, input validation to prevent injections, and implementing proper access control checks. For sensitive data, I ensure it's encrypted at rest and use secure headers like Content Security Policy to prevent common attacks.
Benjamin: What is your experience with implementing rate limiting in APIs?
Priyanka: I've implemented rate limiting using middleware in Node.js with libraries like `express-rate-limit` and configured rate limiting rules directly in API gateways like NginX or AWS API Gateway. This protects against DDoS attacks and ensures that no single user can monopolize resources.
Benjamin: Can you demonstrate how you would optimize an API endpoint that’s performing poorly?
Priyanka: Certainly. I start with profiling and identifying bottlenecks using tools like New Relic or even the Spring Boot Actuator. If a database query is slow, I look into indexing or optimizing the query. For an endpoint, here's an example optimization using caching in Spring:

Benjamin: How do you approach writing unit tests for your APIs?
Priyanka: I follow Test-Driven Development (TDD) principles, writing tests before the actual code. I use frameworks like JUnit and Mockito for mocking dependencies. Here's an example unit test in a Spring Boot application:
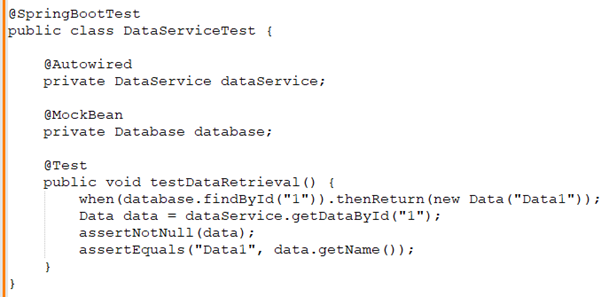
Benjamin: What strategies do you use for debugging a failing API that’s in production?
Priyanka: In production, I use centralized logging with correlation IDs to trace requests across services. Tools like Sentry help me to capture errors in real-time. I also use monitoring dashboards to track the health of the APIs and can roll back to previous versions if necessary.
Benjamin: Can you discuss a particularly challenging API you’ve developed and how you tackled the issues you faced?
Priyanka: One challenge was developing an API that integrated with several legacy systems. I used the Strangler Fig pattern to incrementally replace specific pieces of functionality. To deal with different data formats, I implemented adapters that would translate between the formats used by the legacy systems and the new API.
Benjamin: How do you stay current with the evolving API technologies and best practices?
Priyanka: I stay current by following industry thought leaders, participating in developer forums, attending webinars and conferences, and contributing to open-source projects. Continuous learning is part of my routine, and I allocate time each week to explore new tools and technologies.
Benjamin: Let's dive into a practical scenario. Can you walk us through the process of designing a RESTful API for a simple e-commerce application?
Priyanka: When designing a RESTful API for an e-commerce application, I start with resource identification. For example, resources like `Products`, `Orders`, and `Users`. I define endpoints using nouns and HTTP verbs to denote actions. For instance, `GET /products` to list products and `POST /orders` to create an order.
I would also design the data models and relationships, ensuring they're normalized to avoid redundancy. Here's an example endpoint in a Spring Boot application:

Benjamin: Security is crucial. How do you ensure the security of APIs? Please provide examples of security measures you have implemented.
Priyanka: To ensure API security, I employ HTTPS to encrypt data in transit. I use OAuth for secure and scalable user authentication. For example, in a Spring Boot application, I would configure Spring Security to use OAuth 2.0:

Additionally, I add input validation to prevent injection attacks and configure API gateways with rate limiting and WAF for an extra layer of security.
Benjamin: Versioning is a common challenge. Describe how you would handle versioning in APIs.
Priyanka: For API versioning, I prefer using URI versioning due to its simplicity and visibility. For instance, prefixing the API endpoint with `/v1/`, `/v2/`, etc. I maintain backward compatibility as much as possible and provide clear deprecation policies. Here’s an example of versioning in a controller:

Benjamin: Documentation is important. What is your approach to documenting an API? Which tools do you prefer to use for documentation?
Priyanka: My approach to documenting an API is to keep it updated as the code evolves. I prefer using Swagger with OpenAPI for documentation because it provides a UI to test the endpoints, and it's easy to keep the documentation in sync with the code. Annotations in the codebase help generate the documentation automatically:
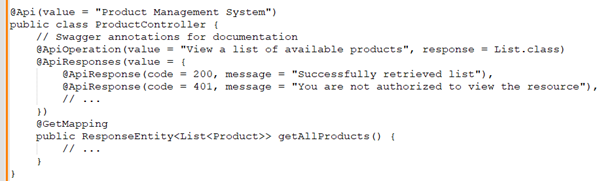
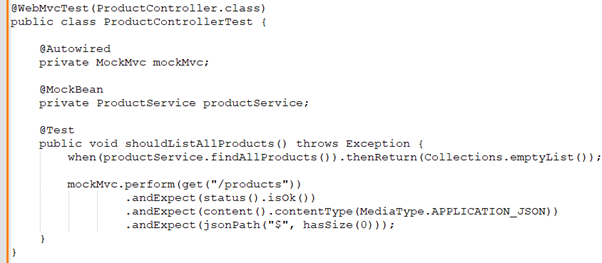
Benjamin: Testing is critical for reliability. How do you test APIs? Please discuss any frameworks or tools you use for testing.
Priyanka: I use JUnit for unit testing and Spring's `MockMvc` for integration testing. I also use Postman for manual API testing and automation tests. Here's an example of a test using `MockMvc`:
Benjamin: What if an API endpoint is slow? Explain how you would optimize the performance of a slow API endpoint.
Priyanka: To optimize a slow API endpoint, first I profile to identify the bottleneck. If it’s a database query, I’ll optimize the query or add indexes. If it’s due to heavy processing, I might add caching with a solution like Ehcache, or consider asynchronous processing or batching requests. Here’s an example with caching in a service method:

Benjamin: Rate limiting is essential to protect APIs. What strategies do you use to handle rate limiting and throttling in APIs?
Priyanka: I use a combination of server-side rate-limiting using NginX or middleware like `express-rate-limit` for Node.js APIs, and client-side strategies such as exponential backoff in the case of limit reaching. For granular control, I configure rules based on user profiles or API keys.
Benjamin: Integration can be complex. Describe a challenging API integration you've worked on and how you resolved the issues you encountered.
Priyanka: I worked on integrating a payment gateway that had limited documentation. I resolved issues by setting up extensive logging and monitoring, which helped me understand the failure points. I also worked closely with the gateway’s technical team to address the ambiguities and ensure that the integration met security standards.
Benjamin: Authentication and authorization are foundational in API design. How do you manage these aspects in APIs?
Priyanka: I manage authentication using JWT tokens or integrate with identity providers using OAuth for third-party authentication. For authorization, I use Spring Security with role-based access control. I define security rules that map roles to specific permissions, like so:
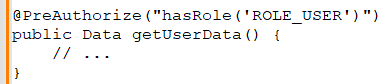
Benjamin: Lastly, the SOAP versus REST debate is ongoing. Can you explain the differences between SOAP and REST APIs and when you might choose one over the other?
Priyanka: SOAP is a protocol with a strict set of standards, requiring XML for message format and usually relying on other application layer protocols for message negotiation and transmission. REST is an architectural style that is more flexible, uses standard HTTP methods, and can support multiple message formats.
SOAP is typically chosen for transactions that require a high level of security and transactional reliability, such as in banking systems. REST is chosen for web services that prioritize scalability, performance, and ease of integration, such as social media platforms.
Benjamin: In microservices, handling API dependencies can be complex. Discuss how you handle API dependencies in microservices architectures.
Priyanka: Managing API dependencies in microservices involves defining clear contracts and using client libraries or SDKs when possible. I use service discovery tools like Eureka or Consul so services can dynamically discover and communicate with each other. Circuit breakers and fallback methods are implemented to handle failures gracefully.
Here's an example of a fallback method using Hystrix in a Spring Boot service:

Benjamin: Error handling is a critical aspect of API design. How do you approach error handling in APIs?
Priyanka: I approach error handling by using HTTP status codes effectively and providing clear error messages. I also structure error responses consistently across the API with an error code, message, and possibly a detailed description. In Spring Boot, I use `@ControllerAdvice` to capture exceptions and convert them into proper HTTP responses.
For example:

Benjamin: Deprecation is inevitable in API lifecycle. Could you provide an example of a time when you had to deprecate an API? How did you manage the transition?
Priyanka: When I had to deprecate an API, I started by versioning the new API and maintaining both versions in parallel. I communicated the deprecation schedule to consumers well in advance, provided detailed migration guides, and offered support during the transition. For critical clients, I created custom solutions to ensure their systems were not disrupted.
Benjamin: Explain the concept of HATEOAS and its role in RESTful APIs.
Priyanka: HATEOAS, or Hypermedia as the Engine of Application State, is a constraint of REST that enables navigation to related resources through hypermedia links. It makes APIs discoverable and self-descriptive. In Spring HATEOAS, it looks like this:

Benjamin: OAuth is a cornerstone of secure API access. What is OAuth, and how have you implemented it in past projects?
Priyanka: OAuth is an open standard for access delegation, used to grant websites or applications access to their information on other websites but without giving them the passwords. I've implemented OAuth in Spring Security, where I configured an OAuth2 authorization server and resource server to secure microservices.
Benjamin: Monitoring APIs is key for maintaining service health. How do you monitor the health and usage of your APIs?
Priyanka: I use a combination of tools like Prometheus for monitoring metrics, Grafana for dashboards, and ELK Stack for logging. I set up custom alerts based on thresholds for error rates, response times, and saturation metrics to proactively address issues.
Benjamin: Backward compatibility is important for users. Discuss how you ensure backward compatibility when making changes to an API.
Priyanka: I ensure backward compatibility by adding new fields or endpoints without altering existing ones, using versioning when introducing breaking changes, and providing deprecation warnings and transition documentation. For instance, adding optional query parameters or request body fields that do not disrupt existing clients.
Benjamin: Consuming third-party APIs comes with its challenges. Describe the process of consuming a third-party API, including handling authentication and error responses.
Priyanka: Consuming a third-party API involves understanding the API's authentication mechanism—like API keys, OAuth tokens—and integrating the necessary authentication flow into the application. I use client libraries or write custom code to handle API requests and parse responses. For errors, I log them and implement retry logic or failover strategies.
For example:

Benjamin: API consumers can vary widely. How do you approach designing an API that will be consumed by both web clients and mobile applications?
Priyanka: I design APIs to be agnostic to the client by focusing on RESTful principles. I use responsive data payloads and consider the bandwidth and latency issues that mobile clients might face. I also leverage caching headers and gzip compression to optimize for performance. Versioning allows me to tailor features or data payloads to specific client types if necessary.
Benjamin: Can you give us insight into a specific API project you've worked on and the stack you used?
Priyanka: On a recent project, I built a set of APIs for a financial service provider. The stack included Spring Boot for the microservices, Spring Cloud for configuration and gateway functionality, MongoDB for the NoSQL database, and OAuth2 for security. We containerized the services with Docker and orchestrated them using Kubernetes for scalability and resilience.
The APIs were documented using Swagger and monitored using Prometheus and Grafana.
Benjamin: Let's start from the beginning. Can you explain the steps you take from developing an API to deploying it in a production environment?
Priyanka: The journey from development to production starts with local development and unit testing. Once the API is developed, I use a version control system like Git for source code management. Then, I push the code to a CI/CD pipeline, which runs tests, linters, and security checks. Upon successful testing, the code is containerized using Docker and pushed to a container registry.
Finally, it's deployed to the production environment using an orchestration tool like Kubernetes, which also handles the service discovery and load balancing.
Benjamin: Managing different environments is essential. How do you manage different environments, like development, testing, and production for API deployment?
Priyanka: I use infrastructure as code tools like Terraform to maintain consistency across environments. Each environment has its configuration files that define the necessary resources. Environment variables and secrets management tools like Vault are used to handle environment-specific configurations.
CI/CD pipelines are configured to deploy to these environments based on the branch or tag in the version control system.
Benjamin: Security is non-negotiable. What are some of the security best practices you follow when deploying an API?
Priyanka: I ensure that APIs are only accessible over HTTPS to protect the data in transit. I use automated tools to scan for vulnerabilities in dependencies before deployment. Access to the APIs is restricted by firewalls and security groups, and I use API keys or OAuth tokens for authentication. Logging and monitoring are set up to detect and alert on suspicious activities immediately.
Benjamin: Versioning is a common challenge. Describe how you would handle versioning when deploying APIs.
Priyanka: I use semantic versioning for APIs and ensure that the version is part of the API endpoint path or header. This way, multiple versions can be deployed and run simultaneously. The CI/CD pipeline is configured to handle deployments based on version tags, and I communicate version deprecations well in advance to the consumers.
Benjamin: CI/CD is crucial for modern deployments. What tools and technologies are you familiar with for CI/CD in the context of API deployment?
Priyanka: I'm familiar with Jenkins, GitLab CI, and GitHub Actions for CI/CD. These tools can automate the testing and deployment process, handle parallel builds, and integrate with other tools for monitoring and notifications. They support containerized applications, which is a common pattern in API deployment.
Benjamin: Post-deployment monitoring is vital. How do you monitor the health and performance of APIs post-deployment?
Priyanka: Post-deployment, I use monitoring tools like Prometheus for gathering metrics and Grafana for visualizing them. I set up alerts in these tools for any anomalies in error rates, response times, or resource usage. APM tools like New Relic or Dynatrace are also used to get detailed performance insights.
Benjamin: Dependency management can be tricky. Explain how you manage API dependencies during deployment.
Priyanka: During deployment, I ensure that all API dependencies are packaged with the application, usually in a Docker container. I use tools like Docker Compose for local development and Kubernetes for production, which allow me to define and manage inter-service dependencies clearly.
Benjamin: Automation is key. How would you automate the API deployment process?
Priyanka: I automate API deployment by setting up a CI/CD pipeline that includes steps for code checkout, running tests, building the application, containerization, and finally deploying to the chosen environment. Here’s an example of a CI/CD pipeline script for a tool like Jenkins:

Benjamin: High availability is crucial for production. What strategies do you use to ensure high availability and fault tolerance for APIs in production?
Priyanka: To ensure high availability, I deploy APIs across multiple data centers or cloud regions. I use load balancers to distribute traffic and implement auto-scaling to handle load changes. For fault tolerance, I use replication, clustering, and implement fallback methods and circuit breakers to gracefully handle service disruptions.
Benjamin: Troubleshooting in production can be stressful. Can you talk about a time when you had to troubleshoot a deployment issue in production? What was the issue and how did you resolve it?
Priyanka: In a previous project, we had an issue where the API was intermittently failing post-deployment. I used logging and tracing to isolate the issue to a service that was reaching its connection pool limit. By analyzing the traffic patterns and code, I found a bug where connections weren't being closed properly.
I fixed the bug, updated the connection pool configuration, and rolled out a patch, which resolved the issue.
Benjamin: Documentation is crucial. How do you manage API documentation during the deployment phase?
Priyanka: API documentation is treated as part of the codebase. I use Swagger or OpenAPI specifications, which are versioned along with the code. During the deployment phase, the CI/CD pipeline includes a step to automatically update the API documentation hosted on our internal or external portal. Here's an example step in a CI/CD script that updates Swagger documentation:
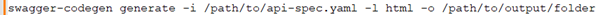
Benjamin: Rate limiting is essential for API stability. What are your strategies for API rate limiting and throttling?
Priyanka: My strategies for rate limiting include implementing a token bucket algorithm at the API gateway level and configuring it per client or user. For throttling, I set up dynamic limits based on the system's current load and use a 429 Too Many Requests status code to signal clients to slow down.
For critical endpoints, I use more sophisticated algorithms like adaptive throttling.
Benjamin: Backward compatibility is key for client trust. How do you ensure backward compatibility of APIs when deploying new versions?
Priyanka: I ensure backward compatibility by following a strict versioning policy, adhering to the contract-first approach, and never making breaking changes within a major version. Deprecated fields are marked and not removed until a major version change. Automated tests are in place to verify that new changes do not break existing functionality.
Benjamin: Rolling back can be as important as rolling out. Describe the process of rolling back an API deployment if something goes wrong.
Priyanka: If a deployment goes wrong, I initiate a rollback using the orchestration tool's built-in mechanisms, like Kubernetes' `kubectl rollout undo` command, which reverts to the previous stable version of the API. This process is automated in the CI/CD pipeline and can be triggered manually if necessary.
Benjamin: Securing sensitive data is paramount. What is your approach to securing API keys and sensitive data during deployment?
Priyanka: I use secrets management tools like HashiCorp Vault or AWS Secrets Manager to handle API keys and sensitive data. These tools securely store and tightly control access to tokens, passwords, and certificates. The CI/CD pipeline retrieves these secrets at deployment time without exposing them in the code or configuration files.
Benjamin: API gateways are often the workhorses of API management. Can you explain the role of API gateways in deployment?
Priyanka: API gateways play a critical role in deployment by providing a single entry point for managing, securing, and routing API calls. They handle cross-cutting concerns like authentication, SSL termination, and rate limiting. During deployment, the gateway's configuration is updated to route traffic to the appropriate services and manage changes in versioning.
Benjamin: Schema migrations can be tricky. How do you handle schema migrations for APIs that rely on a database?
Priyanka: I handle schema migrations using version-controlled migration scripts with tools like Flyway or Liquibase. These scripts are applied automatically during the deployment process. I ensure migrations are backward compatible, and I can roll back changes if needed. For complex migrations, I employ the expand and contract pattern.
Benjamin: Blue-green deployments can be a safety net. What is blue-green deployment, and how could it be useful for API deployment?
Priyanka: Blue-green deployment is a strategy where two identical environments—the "blue" and "green"—run in parallel. One environment is active, handling production traffic, while the other is idle. During deployment, the idle environment is updated and tested. If everything checks out, traffic is switched over, which makes it easy to rollback and minimizes downtime.
Benjamin: Load testing ensures scalability. How do you implement load testing for your APIs before deployment?
Priyanka: I implement load testing using tools like JMeter or Gatling to simulate traffic and assess how the API performs under stress. These tests are run in a staging environment that mirrors production. I monitor response times, error rates, and system resources to ensure the API can handle expected loads.
Benjamin: Optimization is a continuous process. Can you describe a scenario where you optimized the performance of a deployed API? What changes did you make and why?
Priyanka: In a deployed API, I noticed increased latency and resource utilization during peak hours. By analyzing the metrics, I identified inefficient database queries as the culprit. I optimized the queries, added necessary indexes, and implemented caching for frequently accessed data. These changes significantly reduced latency and improved the overall performance of the API.
Benjamin: Designing for Kubernetes requires careful planning. Explain how you would design a RESTful API for a Kubernetes-based application. What are the key considerations?
Priyanka: Designing a RESTful API for a Kubernetes-based application involves considering containerization, service discovery, and configuration management. APIs should be stateless and horizontally scalable to align with Kubernetes' model. I also take advantage of Kubernetes' features like ConfigMaps and Secrets for managing configuration and sensitive data.
The API should be designed to handle dynamic scaling and should be resilient, implementing patterns like retries and circuit breakers to cope with the ephemeral nature of pods.
Benjamin: Kubernetes is becoming a standard for cloud deployment. Describe your experience in deploying and managing APIs within Kubernetes clusters. Can you walk us through a specific example?
Priyanka: In my experience with Kubernetes, I've deployed APIs using Docker containers orchestrated by Kubernetes. For example, I define deployment configurations specifying the Docker image, replicas, and resource limits. Then, I create a service to expose the API and use an Ingress controller for routing external traffic.
Here’s an example deployment configuration:
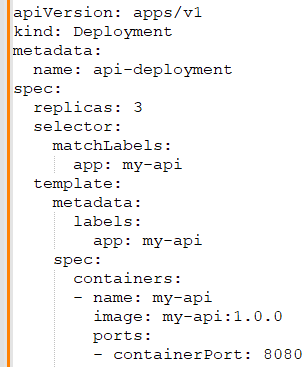
Benjamin: Security is critical. How would you secure APIs in a Kubernetes environment?
Priyanka: To secure APIs in Kubernetes, I use network policies to restrict traffic flow between pods. For authentication and authorization, I integrate with an identity provider using OAuth or OpenID Connect. I might deploy a service mesh like Istio to manage secure service-to-service communication with mTLS.
Secrets are stored using Kubernetes Secrets and injected into pods as environment variables, like so:

Benjamin: API testing is as important as the build itself. What tools and techniques have you used for API testing in Kubernetes?
Priyanka: For API testing in Kubernetes, I've used Postman for manual testing and its Newman command-line collection runner for automation. I also use Kubernetes Jobs to run test suites as part of the CI/CD pipeline. For example, a Job definition to run tests might look like this:
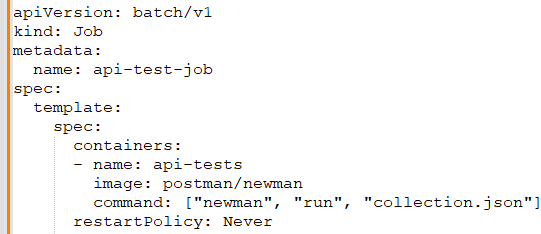
Benjamin: Versioning is vital for API lifecycle management. How do you handle API versioning in Kubernetes?
Priyanka: I handle API versioning in Kubernetes by deploying different versions as separate services, which allows me to run multiple versions concurrently. I use Kubernetes Ingress to route traffic to the appropriate version based on the URL path or header. For instance, `v1` of the API might be routed differently than `v2`.
Benjamin: Scaling is a key feature of Kubernetes. Explain the process of scaling APIs in Kubernetes.
Priyanka: To scale APIs in Kubernetes, I define Horizontal Pod Autoscalers that automatically scale the number of pod replicas based on CPU or memory usage thresholds. Here’s a sample HPA definition:
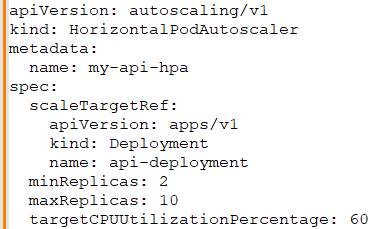
Benjamin: Monitoring is key for performance. What strategies would you use to monitor the performance of APIs deployed on Kubernetes?
Priyanka: For monitoring, I use Prometheus to scrape metrics from my APIs and set up Grafana dashboards for visualization. I also integrate logging solutions like ELK Stack or Fluentd for log aggregation and analysis. Kubernetes liveness and readiness probes are used to monitor the health of the APIs at the container level.
Benjamin: Inter-service communication can be a hurdle. Discuss how you handle API dependencies in Kubernetes.
Priyanka: I manage API dependencies in Kubernetes by using services to provide a stable interface to dependent pods and defining the order of deployment when there are startup dependencies. I also use service discovery mechanisms provided by Kubernetes to dynamically discover and communicate with other services.
Benjamin: Troubleshooting is an essential skill. Can you explain a situation where you had to troubleshoot a failing API in a Kubernetes environment?
Priyanka: I had to troubleshoot an API that was failing due to database connection issues. I used `kubectl logs` to identify the errors and `kubectl exec` to interact with the pod. After pinpointing the issue to connection timeouts, I adjusted the database client configuration in the API to handle intermittent connectivity issues.
Benjamin: High availability is a must. How do you ensure high availability of APIs in Kubernetes?
Priyanka: I ensure high availability by deploying APIs across multiple nodes and, if possible, across multiple availability zones. I use rolling updates for deployments to ensure that there is no downtime during updates. I also implement PodDisruptionBudgets to minimize downtime during node maintenance.
Benjamin: Challenges are inevitable. What are some of the challenges you have faced while working with APIs in Kubernetes and how did you overcome them?
Priyanka: One challenge is managing persistent connections in a dynamic environment like Kubernetes, where pods may be killed or moved frequently. To address this, I’ve implemented graceful shutdowns in my APIs to ensure connections are not abruptly closed. Another challenge is debugging microservices, which I've addressed by implementing distributed tracing using tools like Jaeger or Zipkin.
Benjamin: Deployment strategies are important. Describe your process for updating or rolling back an API in a Kubernetes cluster without causing downtime.
Priyanka: I use a rolling update strategy provided by Kubernetes to update an API. This updates pods incrementally with zero downtime. If an update fails or needs to be rolled back, I use the `kubectl rollout undo` command, which reverts to the previous stable version. Here’s how you can update and rollback deployments:

Benjamin: Kubernetes' native features are powerful. How do you use Kubernetes' native features to manage the lifecycle of APIs?
Priyanka: Kubernetes' native features like Deployments, StatefulSets, Jobs, and CronJobs are utilized to manage the lifecycle. Deployments ensure that a specified number of pod replicas are running at any given time. StatefulSets are used for APIs that require stable, unique network identifiers. Jobs and CronJobs manage batch and scheduled tasks, respectively.
Lifecycle hooks and probes are defined for graceful startup and shutdown.
Benjamin: Service meshes are becoming a trend. Discuss the role of service mesh in managing APIs in Kubernetes.
Priyanka: A service mesh like Istio or Linkerd provides a dedicated infrastructure layer for handling service-to-service communication, which allows for more complex operational requirements such as secure service communication, observability, and traffic control. I've used Istio to enforce mTLS for secure in-cluster communication and to manage traffic patterns for canary deployments.
Benjamin: Rate limiting is crucial for resource management. Explain how you would implement rate limiting and throttling for an API in Kubernetes.
Priyanka: In Kubernetes, I’d implement rate limiting and throttling at the Ingress controller level or by integrating a service mesh like Istio, which has built-in rate limiting capabilities. For example, with Istio, you can set up rate limiting using a policy like this:
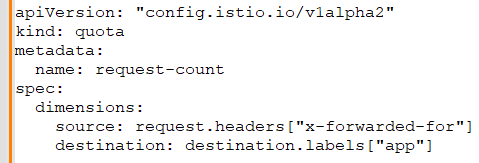
Benjamin: Ingress Controllers are key for managing external access. Describe your experience with using Kubernetes Ingress Controllers for API management.
Priyanka: I’ve used NginX and Traefik as Ingress Controllers for routing external HTTP traffic to the appropriate services within a Kubernetes cluster. A challenge I've faced is configuring SSL/TLS certificates for multiple domains, which I addressed by automating certificate provisioning and renewal with Let's Encrypt.
Benjamin: Stateful APIs require special handling. How do you ensure data persistence and consistency for stateful APIs in Kubernetes?
Priyanka: For stateful APIs, I use StatefulSets in Kubernetes, which provide stable persistent storage and unique network identifiers. PersistentVolumeClaims are used to ensure that data is not lost when pods are rescheduled. For consistency, I implement transactional integrity in the API logic and use databases that support replication and strong consistency models.
Benjamin: Custom resources can extend Kubernetes' functionality. Can you explain the role of Custom Resource Definitions (CRDs) in extending Kubernetes API? Have you created any CRDs?
Priyanka: CRDs allow for extending Kubernetes with custom resources. They enable us to define custom APIs that the Kubernetes API server can handle. I’ve created CRDs to define custom resources for domain-specific requirements, such as a `BackupPolicy` CRD to manage backup configurations declaratively.
Benjamin: Documentation is as essential as development. What is your approach to documenting APIs in a Kubernetes environment?
Priyanka: For documenting APIs in a Kubernetes environment, I use Swagger or OpenAPI. I ensure the documentation is part of the CI/CD pipeline, automatically updating whenever the API changes. I also use annotations in Kubernetes manifests to document how services, Ingress rules, and other resources are used by the API.
Benjamin: Third-party integrations are common. Have you integrated any third-party APIs into a Kubernetes-based application?
Priyanka: Yes, I have integrated third-party APIs such as payment gateways and SMS services into Kubernetes-based applications. I use Kubernetes secrets to manage third-party credentials securely, and I handle error responses and retries in the application code to deal with the third-party service's unavailability.
Benjamin: Custom resources are quite useful. How would you design a Kubernetes API to manage a custom resource?
Priyanka: To design a Kubernetes API for a custom resource, I’d first define a CRD for the resource, then use the Kubernetes Operator pattern to manage the lifecycle of the resource. The Operator would include application-specific logic to handle the creation, update, and deletion of the custom resource instances.
Benjamin: Lastly, kubectl is a fundamental tool. Describe the steps to access the Kubernetes API using kubectl.
Priyanka: To access the Kubernetes API using kubectl, you need to have a configured kubeconfig file with the necessary context, cluster, and user details. You can then use kubectl commands to interact with the cluster, such as `kubectl get pods` to retrieve pods or `kubectl create -f resource.yaml` to create resources defined in a YAML file.
To directly interact with the Kubernetes API, you can use the `kubectl proxy` command to run a proxy to the Kubernetes API server.
Benjamin: Monitoring is key for performance. How do you monitor API performance and what metrics are most critical in Kubernetes?
Priyanka: In Kubernetes, I monitor API performance using Prometheus to collect metrics and Grafana for visualization. Critical metrics include request rate, error rate, response times, and system resource usage like CPU and memory. I also track custom metrics specific to the API's functionality, such as transaction volumes or user concurrency levels.
Benjamin: Persistent storage is essential. Demonstrate how to use the Kubernetes API to create a persistent volume.
Priyanka: To create a Persistent Volume (PV) using the Kubernetes API, you define a PersistentVolume resource in YAML and use `kubectl apply` to create it. Here's an example of a PersistentVolume definition:
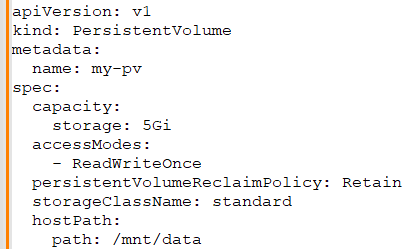
And to create it:
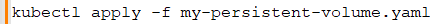
Benjamin: Scalability is a benefit of Kubernetes. How can you use the Kubernetes API to scale deployments programmatically?
Priyanka: To programmatically scale deployments in Kubernetes, you can use the Kubernetes REST API or client libraries in languages like Go, Python, or Java. Here's an example using the Python client:

Benjamin: Troubleshooting is a daily task. If a pod is failing to communicate with an API, what steps would you take to troubleshoot the issue?
Priyanka: I would first check the pod logs using `kubectl logs` to identify any immediate errors. Next, I would verify network policies and service configurations to ensure proper communication paths. I would also inspect the pod’s events using `kubectl describe pod` to see if there are any network-related issues reported by Kubernetes.
Benjamin: Updates need to be smooth. Can you walk me through the process of updating a Kubernetes API without downtime?
Priyanka: To update a Kubernetes API without downtime, I'd use a rolling update strategy. This can be done by updating the Deployment with a new image:
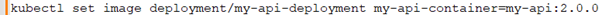
Kubernetes will gradually replace the old pods with new ones, ensuring that there is no downtime.
Benjamin: Security is non-negotiable. How would you restrict access to a certain Kubernetes API endpoint?
Priyanka: To restrict access, I would use Kubernetes Role-Based Access Control (RBAC) to define roles and role bindings that limit which users or services can access certain API endpoints. For example, I could create a Role that only allows read operations and bind it to a specific user or service account.
Benjamin: Automation is crucial. Explain how you would use an API to automate the deployment process in Kubernetes.
Priyanka: I would use the Kubernetes API in a CI/CD pipeline to automate deployments. Upon a successful build and test phase, I'd programmatically apply the updated Kubernetes manifests to the cluster using `kubectl apply` or the Kubernetes client libraries.
Benjamin: Networking is complex. Provide an example of how you would use the Kubernetes API to manage network policies.
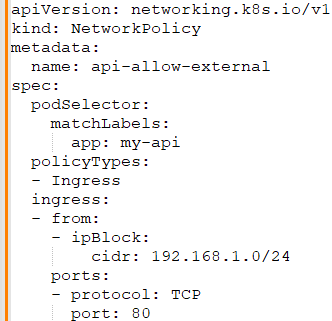
Priyanka: To manage network policies via the Kubernetes API, you define a NetworkPolicy resource that specifies the ingress and egress rules, then apply it using `kubectl`. For example:
And apply it with:
This NetworkPolicy would allow traffic from the specified CIDR block to the `my-api` application on port 80.
Benjamin: Priyanka, I must say, your grasp of Kubernetes and API lifecycle management is impressive. Congratulations on successfully navigating these technical questions. I'm pleased to inform you that you've advanced to the next round of interviews. Your next discussion will be with the Associate Director of our Central IT Team, which focuses on cloud infrastructure and deployment, as well as Kubernetes management.
Please prepare to delve deeper into infrastructure strategies, cloud-native solutions, and orchestration challenges. We're looking forward to your insights on how to streamline our deployment processes and manage our growing suite of services effectively. Good luck, and we are excited to see how you might contribute to our team's success.
Priyanka: Thanks Benjamin, it was really great experience and unprecedented interview for me. I had learnt lot of this concepts regularly from ReadioBook.com platform and applied in my regular work. This indeed great platform you should try to use the same.

ReadioBook.com