
Hello and Welcome to ReadioBook.com. In this ReadioBook, we are going to cover entire syllabus of Cloudera CDP Data Engineer: CDP-3002.
Now let's understand each topic related to Cloudera Data Engineer Certification. We are also going to provide you Certification Preparation Questions and Answers with detailed expatiation. However, in this book our focus will be on fundamental concepts which are being asked or evaluated. As you are well aware our contents are available on below three platforms.

- QuickTechie.com.
- HadoopExam.com.
- ReadioBook.com.So, use any of the above platform to access the material.
About Cloudera Data Engineer Certification: In this exam you will be evaluated for the Data Engineering skills on one of the most popular Big data platform globally and pioneer as well. Following are the areas which are considered for a Data Engineer.
- Designing, Developing and Optimizing Data Workflows and pipeline using Cloudera's various available tools.
- You must be considered expert Data Modeler once you pass this exam.
- Various storage concepts for efficiency like storage formats, data partitioning, and schema design.
- You must be well versed in Apache Iceberg.
- You should be expert in Workflow performance Optimization, troubleshoot to find bottlenecks.
- Query optimization like on Hive, Impala.
- Modern security configuration awareness.
- Cloudera system monitoring.
- Integrating various cloud platforms like AWS, Azure and GCP.
- And platforms like Apache Spark, Kubernetes and Airflow.
About Real Exam:
- Exam Number is: CDP-3002.
- Total Number of Questions asked: 50.
- Exam Duration: 90 Minutes.
- Passing Score: 55%.
- Delivery mechanism: Online.
- Resource available during exam: None.
- Reference Material: None.
So, lets directly jump to the first topic Apache Spark which has 48% weightage. Means, almost 24 questions from this area. Hence, it is very-very critical you have good understanding of Apache Spark on Kubernetes as well as creating solutions for data engineering using Apache Spark. We will go through in detail for these concepts. As per mentioned syllabus following five topics covered.
- Fundamentals on Spark over Kubernetes.
- Work with DataFrames.
- Understand Distribute Processing.
- Implement Hive and Spark Integration.
- Understand Distributed Persistence.
Chapter 1: Spark (Score Coverage 48%)
Topic: Fundamentals on Spark over Kubernetes:
As you embark on the topic of Cloudera Data Platform (CDP) and Spark on Kubernetes in this certification course, it's essential to understand the synergy they create. CDP, with its robust data management capabilities, is integrated seamlessly with Apache Spark's distributed processing prowess, all within the scalable and flexible environment of Kubernetes. This combination provides a dynamic platform for handling big data challenges.

Kubernetes steps in to bring dynamic resource allocation and autoscaling, ensuring Spark jobs are executed efficiently and cost-effectively. This innovative integration results in a platform that not only bolsters Spark's agility and scalability but also simplifies the deployment of Spark applications. It allows data engineers and scientists to shift their focus from infrastructure management to deriving valuable insights.
Overall, CDP and Spark on Kubernetes represent a next-generation approach in data management and analytics. They address modern data processing needs with efficiency and adaptability, making them ideal for meeting the diverse and evolving requirements of big data analysis in various enterprise contexts. Below are the topics, which should be covered under this section.
Spark on Kubernetes Integration: This section will serve as a gateway to understanding how Apache Spark, a powerful in-memory data processing engine, harmoniously integrates with Kubernetes.
This integration represents a paradigm shift in how big data applications are deployed and managed, combining Spark's exceptional data processing capabilities with the operational efficiencies of Kubernetes. It's not just about running Spark jobs; it's about embracing a more dynamic, scalable, and flexible approach to data processing in the cloud-native era.
Through this integration, Spark inherits Kubernetes' abilities in container management, allowing for a more streamlined and efficient resource utilization. The orchestration provided by Kubernetes simplifies the deployment, scaling, and management of Spark applications, enabling a more agile and responsive data processing environment.
In this topic, we'll explore the architectural aspects of Spark on Kubernetes, including how Spark jobs are containerized and scheduled. We'll also delve into the practicalities of this integration, including setup, configuration, and optimization techniques, ensuring that you have a comprehensive understanding of how to leverage Spark's data processing power within a Kubernetes-managed environment.
Concept 1: Spark Application Packaging:
Packaging Spark applications involves bundling the application code along with its dependencies into a format that is easily deployable within the CDP environment.
Understanding Spark Application Structure:
Spark Application Components: A typical Spark application consists of a driver program and multiple executor processes. The driver program runs the main() function of the application and executes various parallel operations on the cluster. The components of a Spark application are:
- Driver, Application Master.
- Spark Context.
- Executors.
- Cluster Resource Manager.
All Spark components run in Java Virtual Machines (JVMs). JVMs are cross-platform runtime engines that execute instructions compiled into Java bytecode.
Dependencies: Spark applications often depend on external libraries. Managing these dependencies is crucial for the application's successful execution.
Packaging Spark Applications:
- Build Tools: Introduction to build tools like Maven for Java/Scala or setuptools for Python.
- Creating a Build File: Writing a pom.xml for Maven or a setup.py for setuptools, specifying project properties and dependencies.
- Building the Package: Running build commands to create a JAR (Java/Scala) or a Wheel/EGG (Python) package.
Packaging a PySpark application, including its dependent libraries, for deployment involves several key steps. Here, we'll walk through the process step by step, using a simple example application. This process includes setting up your environment, writing the application, managing dependencies, and finally packaging and deploying the application.
Step 1: Setting Up the Development Environment:
- Install Python: Ensure Python is installed on your system. PySpark typically supports Python 3.6 and later.
- Install Apache Spark: Download and install Apache Spark from the.
- Set Environment Variables: Set `SPARK_HOME` and update the `PATH` variable.
- Install PySpark: Install PySpark using pip:
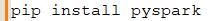
Step 2: Creating a PySpark Application:
- Create a New Directory: Make a new directory for your project.

- Create a Python File: Create a new Python file for your application, e.g., `app.py`.
- Write a Simple PySpark Application:

Step 3: Managing Dependencies.
- Identify Dependencies: Determine any third-party libraries your application needs.
- Create a `requirements.txt` File: List all dependencies.
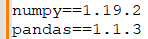
- Install Dependencies Locally: Use pip to install these dependencies.
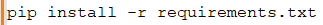
Step 4: Packaging the Application: Using `setuptools` for Packaging:
- Create a `setup.py` file in the project root with the following content:

- Building the Package: Run the following command to create a distributable package:
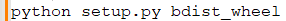
- This will create a wheel file in the `dist` directory.
Step 5: Deploying the Application:
- Prepare Your Spark Cluster: Ensure your Spark cluster is ready and accessible.
- Upload Your Application: Upload the wheel file and your `app.py` to an accessible location on your Spark cluster or a storage bucket.
- Submit the Spark Job:
- Use the `spark-submit` command to submit your job:
- `--py-files` includes the packaged dependencies.
In the process described above, we are packaging and deploying a PySpark application for use in a distributed environment like Apache Spark. Initially, we set up the development environment by installing Python, Apache Spark, and PySpark. Then, we create a simple PySpark application script, `app.py`, which reads and displays data from a CSV file using Spark's DataFrame API. After writing the application, we manage its dependencies by listing them in a `requirements.txt` file and installing them locally.
The next step involves packaging the application for distribution. We use `setuptools`, a Python utility, to package the application and its dependencies into a Wheel file, a built distribution format for Python. This packaging is crucial for ensuring that all dependencies are available in the Spark environment when the application runs.
Finally, we deploy the application by uploading the Wheel file and the `app.py` script to our Spark cluster. We use the `spark-submit` command, specifying our Wheel file with the `--py-files` option, to execute our application on the cluster. This command tells Spark to distribute the Wheel file across the nodes in the cluster, making the dependencies available wherever the application is executed. This entire process exemplifies how a PySpark application is prepared and deployed in a scalable and distributed manner on a Spark cluster.
Spark Driver in Kubernetes: The Spark Driver is a critical component, acting as the orchestrator of Spark applications. Understanding how the Spark Driver operates within a Kubernetes environment is essential for deploying and managing Spark applications efficiently.
Spark Driver Basics:
Role and Responsibilities: The Spark Driver is responsible for converting a user application into tasks and scheduling them on Executors.
In a Spark application, particularly when using PySpark, the Spark Driver plays a crucial role in orchestrating and managing the execution process. Understanding its responsibilities and how it operates is key to effectively utilizing Apache Spark, especially in distributed environments like Kubernetes.
In Spark, the Driver is the central coordinator, translating user code into executable tasks, scheduling them on Executors, and managing their execution. In a Kubernetes environment, its role extends to interacting with the Kubernetes API, managing resources, and ensuring efficient communication and high availability. Understanding these aspects is fundamental for developing and managing efficient Spark applications in distributed systems. Here's a detailed breakdown of the role and responsibilities of the Spark Driver in the context of PySpark:
Application Interpretation and Execution Planning:
- The Spark Driver first takes the user application written in PySpark and interprets the code.
- It then constructs a logical plan to execute the application. This involves understanding the transformations and actions defined in the PySpark code.
DAG (Directed Acyclic Graph) Creation:
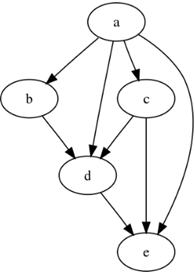
- The Driver translates this logical plan into a physical plan in the form of a DAG. This DAG outlines how different RDD (Resilient Distributed Dataset) transformations are mapped to stages and tasks.
- Each stage in the DAG represents a set of tasks that can be executed in parallel.
Task Scheduling:
- The Driver sends these tasks to the Executors. Executors are worker nodes in the Spark cluster that run these tasks.
- Task scheduling involves deciding which Executor will run which task, based on factors like data locality and resource availability.
Task Monitoring and Execution Management:
- The Driver monitors the execution of tasks on the Executors. It keeps track of their progress and status.
- If a task fails, the Driver is responsible for rescheduling it, possibly on a different Executor.
Shuffling and Aggregation Management:
- For operations that require data shuffling (like reduceByKey), the Driver manages how data is shuffled between different Executors.
- It ensures that the shuffled data is properly aggregated according to the application's logic.
Result Collection and Final Output:
- Once all tasks are complete, the Driver collects the final results. In actions like `collect()` or `take()`, it gathers data from the Executors.
- The Driver then provides the final output to the user application or stores it in the specified data source.
Responsibilities in a Kubernetes Environment: When running in a Kubernetes environment, the Spark Driver has additional responsibilities:
Interacting with Kubernetes API:
- The Driver communicates with the Kubernetes API to request resources for Executors.
- It manages the lifecycle of Executor pods, including their creation and termination.
Handling Cluster Resources:
- The Driver ensures optimal resource utilization within the Kubernetes cluster, managing CPU and memory requests as per the application needs.
Networking and Communication:
- In Kubernetes, the Driver must efficiently manage network communication with Executors, considering the cluster's networking setup.
Fault Tolerance and High Availability:
- The Driver must handle its own failures and ensure high availability, especially crucial in distributed environments like Kubernetes.
Execution Context: In a Kubernetes environment, the Driver can be run inside a pod, ensuring it has access to the cluster's resources. Running the Spark Driver inside a Kubernetes pod offers significant advantages in terms of resource accessibility and management. We will explore how this setup enhances the Spark application's performance and scalability.
Understanding Kubernetes Pods:
- Kubernetes Pod Basics: A pod is the smallest deployable unit in Kubernetes, capable of running one or more containers.
- Pods in Spark Context: In Spark on Kubernetes, the Driver runs in its own pod, which houses the container running the Spark Driver process.
Configuring the Spark Driver Pod:
- Pod Specifications: Setting up the pod specification for the Spark Driver, including CPU, memory, and storage resources.
- Example YAML Configuration:

Deploying the Spark Driver in Kubernetes:
- Using `spark-submit`: How to deploy a Spark application with the Driver running in a Kubernetes pod.
- Example `spark-submit` Command:

Resource Management:
- Dynamic Resource Allocation: Understanding how the Driver manages resources for Executors in Kubernetes.
- Executor Pods Management: How the Driver creates and manages Executor pods based on the application's requirements.
Networking and Communication:
- Driver-Executor Networking: Setting up network communication between the Spark Driver pod and Executor pods.
- Service and Ingress Configuration: Ensuring proper network setup for inter-pod communication.
Advantages of Pod-Based Driver:
- Resource Efficiency: Better resource utilization and management.
- Isolation and Security: Enhanced isolation and security for the Spark Driver.
- Scalability and Flexibility: Improved scalability and flexibility in resource allocation and management.
Spark Executors on Kubernetes: How Spark Executors function within a Kubernetes environment. Spark Executors are crucial for carrying out the tasks assigned by the Spark Driver. In a Kubernetes setup, these Executors are treated as pods, providing a highly scalable and efficient way to handle workloads.
Understanding Spark Executors:
- Executors are worker nodes in a Spark application, responsible for executing tasks and storing data in memory or disk.
- Each Executor runs in its JVM, providing isolation and resource management.
Spark Executors as Kubernetes Pods:
- In Kubernetes, each Spark Executor is launched as an individual pod.
- Pods are the smallest deployable units in Kubernetes and are ideal for hosting Executors.
- This setup allows Executors to leverage Kubernetes' features like self-healing and easy scaling.
Configuration of Executors in Kubernetes:
- Executors require the specification of resources like CPU and memory.
- PySpark example to define resources:

- This code sets up a Spark session with specified resources for Executors running in Kubernetes.
Launching Executors in Kubernetes:
- When a Spark application starts, the Driver communicates with the Kubernetes API to launch Executor pods.
- These pods are created based on the configuration provided in the Spark application.
Dynamic Resource Allocation:
- Spark on Kubernetes supports dynamic allocation of Executors.
- This feature allows Kubernetes to scale up or down the number of Executor pods based on the workload.
- Dynamic resource allocation optimizes resource usage, scaling resources as needed.
Enabling Dynamic Allocation:
- Dynamic allocation can be enabled through Spark configurations.
- Example PySpark configuration for dynamic allocation:

- This setup enables Spark to dynamically adjust the number of Executor pods within the specified range.
Monitoring and Managing Executors:
- Kubernetes tools like `kubectl` can be used to monitor the status and health of Executor pods.
- This includes tracking resource usage, pod status, and logs.
Managing Executor Lifecycle:
- Kubernetes handles the lifecycle of Executor pods, restarting them in case of failures.
- Spark's integration with Kubernetes ensures seamless management of these pods.
Resource Allocation:
Effective resource allocation is crucial in optimizing the performance of Apache Spark applications. In this section, we will delve into two key resource allocation models used with Spark Executors: Dynamic Allocation and Fair Scheduling. We'll explore each model in detail, providing PySpark examples to illustrate their implementation and benefits.
Dynamic Allocation: Dynamic Allocation allows Spark to automatically adjust the number of executors allocated to an application based on its workload. This feature is essential for optimizing resource usage, especially in environments with varying workloads.
Understanding Dynamic Allocation:
- Dynamic Allocation enables adding or removing Spark Executors dynamically based on the workload.
- It minimizes resource wastage and ensures efficient processing.
Fair Scheduling: Fair Scheduling allows resources to be allocated fairly among a set of running jobs, as opposed to Spark's default FIFO (First In, First Out) scheduling. The Fair Scheduler allocates resources to jobs such that all jobs get, on average, an equal share of resources over time.
Setting Up Fair Scheduler in PySpark: To enable Fair Scheduling:

Working with Pools in Fair Scheduling: Jobs can be grouped into pools, and each pool is allocated a certain amount of resources. Example of assigning a job to a specific pool:

Benefits of Fair Scheduling:
- Ensures that long-running jobs don't starve shorter jobs of resources.
- Provides a more equitable sharing of resources in a multi-user environment.
Implementing Both Models: It's possible to implement both Dynamic Allocation and Fair Scheduling in the same environment. Dynamic Allocation adjusts the number of executors, while Fair Scheduling ensures fair distribution of these executors among jobs.
Monitoring and Logging:
Monitoring and logging are crucial for understanding the behavior and performance of Spark applications, especially when running on Kubernetes. This section covers how to use the Spark Web UI and Kubernetes metrics for effective monitoring and logging.
Spark Web UI: The Spark Web UI is a powerful tool for monitoring Spark applications. It provides detailed insights into the execution of jobs, stages, and tasks.
Accessing Spark Web UI in Kubernetes:
- When running Spark on Kubernetes, the Spark Web UI is exposed through a service.
- You can use port forwarding to access the UI: `kubectl port-forward 'spark-driver-pod' 4040:4040`
- Then, access the UI by navigating to `http: //localhost:4040` in your browser.
Understanding Spark Web UI Components:
- Jobs and Stages Tabs: Track job progress and view stage-level details.
- Executors Tab: Provides information on executor-level metrics like memory usage and tasks executed.
- SQL Tab: If using SparkSQL, this tab shows details on SQL query executions.
Spark Hands On Trainings are available on QuickTechie.com website.
Using Spark Web UI for Performance Tuning:
- Identify slow-running tasks or stages.
- Analyze task metrics for memory and CPU bottlenecks.
- Review shuffle read and write metrics to optimize data transfers.
Kubernetes Metrics and Dashboards: Kubernetes provides metrics and dashboards that can be used to monitor the health and performance of Spark applications.
Using Kubernetes Dashboard:
- Deploy the Kubernetes Dashboard to get a visual interface for cluster resources.
- Access detailed metrics about pod CPU and memory usage, including Spark Driver and Executor pods.
Monitoring with Prometheus and Grafana:
- Set up Prometheus to scrape metrics from Kubernetes and Spark.
- Use Grafana to create dashboards that visualize these metrics.
- Sample Grafana dashboard setup:

Collecting Logs for Analysis:
- Use `kubectl logs 'spark-pod-name'` to view logs directly from the Kubernetes command line.
- Integrate with a centralized logging solution like ELK (Elasticsearch, Logstash, Kibana) for more advanced log analysis.
PySpark Example: Tracking Application Metrics: Running a PySpark Application:
- Deploy a PySpark job on Kubernetes.
- Example PySpark job submission:

Monitoring Using Spark Web UI and Kubernetes Metrics:
- Use Spark Web UI to monitor the job's progress and performance.
- Check Kubernetes Dashboard or Grafana for resource utilization and pod health metrics.