
Note: For all 10 chapters, please refer to the navigation section above.
Chapter-2: Interview Question for Python Fundamental Part 2.
Question: What are the benefits of using Python language compare to existing other programming language?
Answer: Python offers several benefits that make it a popular choice among developers:
- Readability and Simplicity: Python's syntax is clear and intuitive, making it an excellent language for beginners and a swift tool for experienced developers to translate thoughts into working code.
- Rapid Development: Its high-level data structures, along with dynamic typing and binding, facilitate rapid application development.
- Extensive Standard Library: Python's comprehensive standard library provides modules and functions for a wide variety of tasks, reducing the need for third-party tools.
- Interoperability: Python can interact with other languages and platforms via libraries, and it's widely supported across operating systems.
- Versatility: It's used in various domains, from web development to data analysis, machine learning, and scientific computing.
- Flexibility: Python supports multiple programming paradigms, including procedural, object-oriented, and functional programming.
- Integrated Development Environments (IDEs): Python's support for numerous IDEs, like PyCharm and VS Code, allows for powerful coding, debugging, and testing environments.
- Open Source: It's free to use and distribute, even for commercial purposes, which can significantly reduce development costs.
- By focusing on these technical aspects, Python positions itself as an adaptable and efficient choice for a wide range of programming tasks.
Question: What is a dynamically typed and static typed language?
Answer: In programming languages, the distinction between dynamically typed and statically typed languages pertains to when the type checking is performed and how variable types are assigned.
Dynamically Typed Languages:
- Type Checking: In dynamically typed languages, type checking is performed at runtime. This means that you don't have to explicitly declare the type of a variable when you write code. The type of a variable is determined at the moment the code is executed, which allows for more flexibility.
- Flexibility: They are generally more flexible in terms of coding, as you can assign different types of data to the same variable at different points in the program.
- Example Languages: Python, Ruby, JavaScript, and PHP are examples of dynamically typed languages.
Statically Typed Languages:
- Type Checking: Statically typed languages require the type of all variables to be explicitly declared and determined at compile-time, before the program is run. This can catch type errors early in the development process.
- Performance: Statically typed languages can be more efficient at runtime because the compiler knows the exact data types that are used and can optimize the execution.
- Example Languages: C, C++, Java, and Swift are examples of statically typed languages.
The key difference is that in dynamically typed languages, the types are associated with run-time values and not named variables/expressions themselves, whereas in statically typed languages, the types are associated with variables/expressions themselves and need to be known at compile-time.
Question: What do you mean by an Interpreted language and in context of Python?
Answer: An interpreted language is a type of programming language for which most of its implementations execute instructions directly and freely, without previously compiling a program into machine-language instructions. The interpreter executes the program directly, translating each statement into a sequence of one or more subroutines and then into another language (often machine code).
In the context of Python: Python is often referred to as an interpreted language because Python code is executed by an interpreter. The standard Python implementation, CPython, compiles Python code into bytecode (which is a low-level set of instructions that is then executed by an interpreter). However, this compiled form is not in the machine language of any computer. The Python interpreter reads this bytecode and translates it into the appropriate machine code for execution.
Here are some characteristics of Python as an interpreted language:
- Ease of Use and Flexibility: Since the code is not compiled before execution, developers can write and test small pieces of code very quickly, which is useful for prototyping and experimental development.
- Portability: Python programs can run on any machine with a compatible interpreter, making Python code platform-independent as long as the interpreter is present.
- Runtime Evaluation: Python can evaluate and execute code at runtime, allowing for dynamic typing, reflection, and introspection, as well as the construction and evaluation of code on-the-fly. However, this interpretation layer can make Python programs run slower than equivalent programs in compiled languages, such as C or C++. To mitigate this, various implementations of Python may use Just-In-Time (JIT) compilation, such as PyPy, to improve execution speeds.
Question: What is PEP 8 and why is it important?
Answer: PEP 8, also known as the Python Enhancement Proposal 8, is the style guide for writing Python code. It was written in 2001. The PEP 8 document provides conventions for the formatting of Python code. This includes guidelines on how to name variables, how to indent your code, how to structure your import statements, and more. The overarching goal of PEP 8 is to improve the readability and consistency of Python code.
PEP 8 is important because:
- Readability: Since Python emphasizes readability, a common style guide helps maintain a uniform style of coding, making it easier to understand the code written by different authors.
- Maintainability: Consistent coding style makes it easier to maintain and update code, which is especially important in collaborative projects or when codebases are handed over to new developers.
- Community Standards: PEP 8 represents a set of rules endorsed by the Python community, which helps in setting a standard that Python developers can adhere to.
- Quality and Productivity: Following PEP 8 can lead to more reliable and maintainable code. It can also increase productivity, as developers spend less time deciphering the styling of the code and more on understanding the logic and implementation.
- Tooling Support: Many development tools, linters, and IDEs have support for PEP 8, providing features like real-time linting and auto-formatting to help developers stick to these guidelines. While PEP 8 is a recommendation and not a compulsory standard, adhering to it is considered good practice in the Python community. It allows programmers to focus on writing code rather than on the layout, and ensures that the large body of Python code available in open-source projects is more or less uniformly styled.
Question: Can you please explain the Scope in Python and how it is impacted. Please give example?
Answer: In Python, scope refers to the region in a program where a namespace is directly accessible. In other words, scope determines the visibility of a variable within the code. The two basic scopes in Python are:
- Local Scope: Refers to variables defined within a function. These variables are only accessible within that function and not outside of it.
- Global Scope: Refers to variables defined outside of a function. These variables are accessible anywhere within the script.
The concept of scope is impacted by where you declare a variable. The LEGB rule is an acronym used to describe the scope resolution process in Python:
- L, Local — Names assigned in any way within a function (‘def’ or ‘lambda’), and not declared global in that function. - E, Enclosing-function locals — Names in the local scope of any and all statically enclosing functions (‘def’ or ‘lambda’), from inner to outer.- G, Global (module) — Names assigned at the top-level of a module file, or declared global in a ‘def’ within the file.
- B, Built-in (Python) — Names preassigned in the built-in names module: ‘open’, ‘range’, ‘SyntaxError’, etc.
Here's an example illustrating local and global scope:
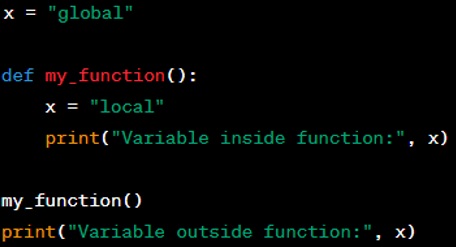
Output you can see as below:

In this example, there are two different ‘x’ variables: one in the global scope (outside the function) and one in the local scope (inside the function). When you print ‘x’ inside ‘my function()’, it prints ‘local’ because the function scope takes precedence. Outside the function, it prints ‘global’ because there is no local scope.
Here is an example that shows how an enclosed function can impact scope:
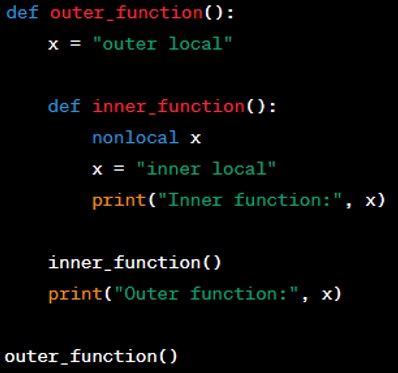
Output you can see as below:
 In the ‘inner function’, we use the ‘nonlocal’ keyword to tell Python that ‘x’ should not be local to ‘inner function’, but rather to the nearest enclosing scope—which is ‘outer function’'s local scope.
So the change to ‘x’ inside ‘inner function’ affects ‘x’ as defined in ‘outer function’.
In the ‘inner function’, we use the ‘nonlocal’ keyword to tell Python that ‘x’ should not be local to ‘inner function’, but rather to the nearest enclosing scope—which is ‘outer function’'s local scope.
So the change to ‘x’ inside ‘inner function’ affects ‘x’ as defined in ‘outer function’.
Question: Can you please explain the difference between list and tuples?
Answer: Certainly! Lists and tuples are both sequence types in Python that can be used to store collections of items. Here are the key differences between them:
Mutability:
- List: Lists are mutable, which means that you can change, add, or remove items after the list has been created.
- Tuple: Tuples are immutable; once a tuple is created, you cannot change, add, or remove items from it.
Syntax:
- List: A list is defined by square brackets ‘[]’.
- Tuple: A tuple is defined by parentheses ‘()’.
Performance:
- List: Lists have a variable size, so they require more memory and incur a greater performance cost for operations like copying, iteration, and deletion.
- Tuple: Tuples have a fixed size and are generally faster than lists when it comes to iteration and have a smaller memory overhead due to their immutability.
Use Cases:
- List: Use a list when you have a collection of items that may change over time, and you need to manipulate the contents of that collection.
- Tuple: Tuples are commonly used for small collections of values that will not need to change, such as the coordinates of a point in 2D space.
Methods:
- List: Lists support several methods that allow you to modify the list, such as ‘append()’, ‘remove()’, ‘pop()’, ‘insert()’, and more.
- Tuple: Tuples do not have methods for adding or removing items. They do, however, support methods for finding elements (‘index()’) and counting occurrences (‘count()’), which do not modify the tuple.
Here is a simple example to illustrate both:
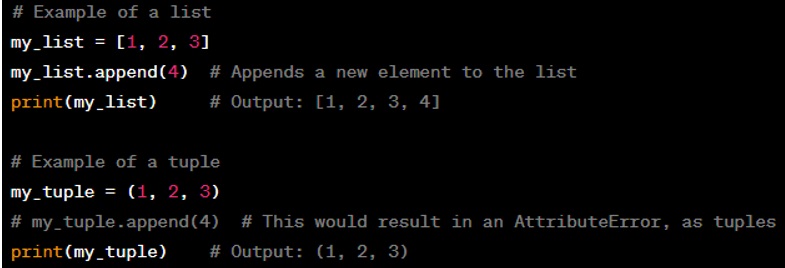 Remember, because tuples are immutable, they can be used as keys in dictionaries, whereas lists cannot.
Remember, because tuples are immutable, they can be used as keys in dictionaries, whereas lists cannot.
Question: Can you please explain pass in Python?
Answer: In Python, ‘pass’ is a statement that serves as a placeholder or a no-operation (no-op); nothing happens when it is executed. It is used when a statement is required syntactically but you do not want any command or code to be executed.
The ‘pass’ statement is commonly used:
As a placeholder for future code. When writing new code, you might use ‘pass’ to indicate a block where code will eventually go, but has not been written yet.
Please see Example below:
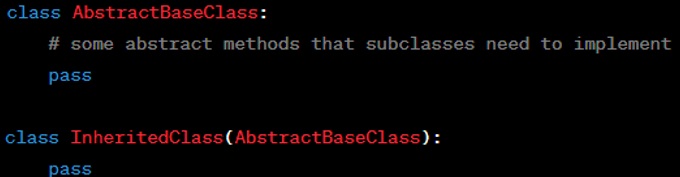
 To define a minimal class or a subclass that inherits all behavior from a parent class without any modifications.
To define a minimal class or a subclass that inherits all behavior from a parent class without any modifications.
Please see Example below:
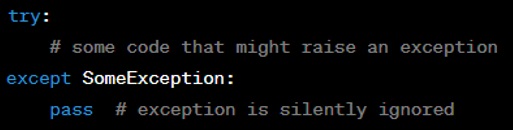
 In exception handling, where you want to catch an exception but handle it by doing nothing.
In exception handling, where you want to catch an exception but handle it by doing nothing.
Please see Example below:
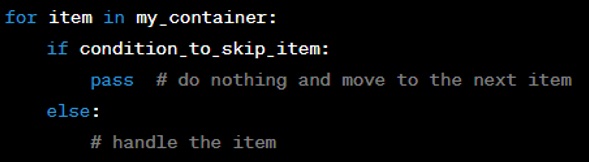
 As a place-filler in a control flow statement where there is required a statement but no action is needed.
As a place-filler in a control flow statement where there is required a statement but no action is needed.
Please see Example below:
 The ‘pass’ statement helps to keep the integrity of the code structure and can be used to make the code syntactically correct while leaving places to insert logic in the future.
It’s effectively used for creating minimal classes or functions, which can then be expanded. Unlike a comment, the ‘pass’ statement is a recognized operation by the Python interpreter, so it can be used in places where Python syntax would otherwise require an executable statement.
The ‘pass’ statement helps to keep the integrity of the code structure and can be used to make the code syntactically correct while leaving places to insert logic in the future.
It’s effectively used for creating minimal classes or functions, which can then be expanded. Unlike a comment, the ‘pass’ statement is a recognized operation by the Python interpreter, so it can be used in places where Python syntax would otherwise require an executable statement.
Question: Can you please explain global, protected and private attributes in Python?
Answer: In Python, the concept of access modifiers like private, protected, and public—as found in some other object-oriented languages—is not enforced by the language itself. However, there is a convention used by Python developers to denote private and protected attributes, using underscores as a prefix.
Here are how these concepts are generally applied in Python:
Public Attributes: By default, all attributes of a class are public, which means they can be accessed from outside the class.
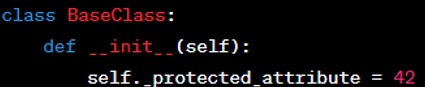
Protected Attributes: These are attributes that are intended to be used only within the base class and its derived classes. By convention, a single underscore ‘ ’ is used as a prefix to the attribute name to indicate that it is a protected member.
Please see Example below:
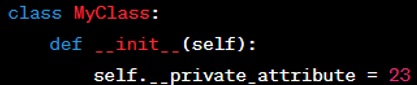
Private Attributes: These are attributes that should not be accessed from outside the class. In Python, double underscores ‘ ’ are used at the beginning of the attribute name to "name mangle" it, which means that the interpreter changes the name of the variable in a way that makes it harder to create subclasses that accidentally override private attributes and methods.
Please see Example below:
 This will mangle the name of the ‘ private attribute’ to something like ‘ MyClass private attribute’, which is not easily accessible from outside of the class.It is important to note that this name mangling is not truly private; it is more accurately described as a way to avoid name clashes in subclasses.
You can still access these "private" attributes if you know the mangled name, which means it’s more about internal use rather than strict enforcement of access. Python does not have an explicit mechanism for protected members. The single underscore is a convention, and it is left to the programmers to respect these conventions about the intended level of access for protected and private members.
Unlike languages such as C++ or Java, which have strict access control, Python’s philosophy is built upon the idea of "we are all consenting adults here," suggesting that class and module authors should trust others to use things properly.
This will mangle the name of the ‘ private attribute’ to something like ‘ MyClass private attribute’, which is not easily accessible from outside of the class.It is important to note that this name mangling is not truly private; it is more accurately described as a way to avoid name clashes in subclasses.
You can still access these "private" attributes if you know the mangled name, which means it’s more about internal use rather than strict enforcement of access. Python does not have an explicit mechanism for protected members. The single underscore is a convention, and it is left to the programmers to respect these conventions about the intended level of access for protected and private members.
Unlike languages such as C++ or Java, which have strict access control, Python’s philosophy is built upon the idea of "we are all consenting adults here," suggesting that class and module authors should trust others to use things properly.
Question: Please explain continue, break and pass in Python?
Answer: In Python, ‘continue’, ‘break’, and ‘pass’ are control statements that alter the flow of a typical loop. Here's a brief explanation of each:
continue: The ‘continue’ statement immediately stops the current iteration of the loop and moves control back to the top of the loop for the next iteration. It's commonly used to skip over certain elements or conditions within a loop.
Please see Example below:
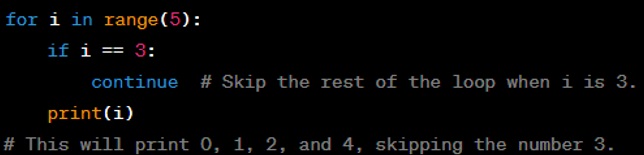
break: The ‘break’ statement is used to exit or "break out" of a loop, regardless of the loop’s normal control structure. It can be used in both ‘while’ and ‘for’ loops. When a ‘break’ is encountered, the loop is terminated immediately, and program control resumes at the next statement following the loop.
Please see Example below:

pass: The ‘pass’ statement does nothing and is used as a placeholder in places where your code will eventually go, but has not been written yet (e.g., in stub functions or classes). It allows you to handle the condition without the loop being impacted in any way. It’s typically used for creating minimal classes or functions to keep the interpreter happy when it expects an indented block.
Please see Example below:
 The ‘pass’ statement is often used for creating minimal classes or functions, as well as serving as a placeholder where the syntax requires an indented block, but no action is required or planned for now. On the other hand, ‘continue’ and ‘break’ are used to control the flow of loops—’continue’ skips to the next iteration, while ‘break’ exits the loop altogether.
The ‘pass’ statement is often used for creating minimal classes or functions, as well as serving as a placeholder where the syntax requires an indented block, but no action is required or planned for now. On the other hand, ‘continue’ and ‘break’ are used to control the flow of loops—’continue’ skips to the next iteration, while ‘break’ exits the loop altogether.
Question: Please explain unit test concept in Python?
Answer: Unit testing is a software testing method where individual units or components of a software application are tested in isolation from the rest of the application. The purpose of unit testing is to validate that each unit of the software performs as designed. A unit is the smallest testable part of any software and usually has one or a few inputs and usually a single output.
In the context of Python, unit testing can be carried out using the ‘unittest’ module, which is included in Python's standard library. Here’s a brief explanation of how you would use it:
Writing Test Cases: You create a subclass of ‘unittest.TestCase’, and then define test methods within this subclass. Each test method should test a specific aspect of the behavior of the code you are writing tests for.
Please see Example below:

Assertions: ‘unittest’ provides a set of assertion methods that can be used to check for various conditions, such as equality, truthiness, or exceptions being raised.
Running Tests: You can run tests by calling ‘unittest.main()’. This runs the test runner by discovering all classes that inherit from ‘unittest.TestCase’ in the current module.
Setup and Teardown: ‘unittest.TestCase’ provides ‘setUp’ and ‘tearDown’ methods that you can override to provide instructions that will be executed before and after each test method, respectively. Unit testing ensures that all code meets quality standards before it's deployed. This is crucial in a test-driven development (TDD) environment, where tests are written before the code and the code is not considered complete until all tests pass.This approach can lead to fewer bugs in production and higher overall code quality.
Additionally, when tests are written well, they also serve as documentation for your code, since they demonstrate how the code is supposed to be used.
Unit testing ensures that all code meets quality standards before it's deployed. This is crucial in a test-driven development (TDD) environment, where tests are written before the code and the code is not considered complete until all tests pass.This approach can lead to fewer bugs in production and higher overall code quality.
Additionally, when tests are written well, they also serve as documentation for your code, since they demonstrate how the code is supposed to be used.
Question: Please explain docstring in Python?
Answer: In Python, a docstring is a string literal that occurs as the first statement in a module, function, class, or method definition. A docstring becomes the ‘ doc ’ special attribute of that object. They're used to explain what the object does, its parameters, return value, and any other important details.
Docstrings are enclosed within triple quotes (‘"""‘ or ‘'''‘), allowing for multi-line descriptions. Here's how they're used in various parts of the code:
Module Docstrings:
At the beginning of a Python file, you might see a docstring that explains what the module contains or its purpose.
Function and Method Docstrings:
Below the ‘def’ line of a function or method, the docstring describes what the function/method does, its parameters, its return value, and any other relevant information.
Class Docstrings:
Right after the class definition, the docstring might explain the purpose of the class and its behavior.
Importance:
Docstrings are important for several reasons:
- Documentation: They are a built-in way of associating documentation with Python code. Tools like Sphinx can auto-generate documentation from docstrings.
- Readability: They improve code readability by providing developers with a quick way to understand what a piece of code is supposed to do without having to read and interpret the logic.
- Introspection: They can be accessed at runtime using the ‘. doc ’ attribute, which is useful for introspection. This feature facilitates practices such as automatic help-text generation and testing.Adherence to proper docstring conventions is considered good practice in Python, and PEP 257 provides a more comprehensive guide on how to write docstrings.
Question: Can you please explain slicing concept in Python with example?
Answer: Slicing in Python refers to the technique of accessing a range or a subsequence of elements from a sequence type, such as lists, strings, tuples, and others. Slicing is done by specifying a start index and a stop index, as well as an optional step index, using a colon ‘:’ to separate them inside square brackets ‘[]’.
The general form of slicing is:
 - ‘start’ (optional) - The starting index of the slice. It defaults to 0 if not provided.- ‘stop’ - The ending index (exclusive) of the slice. The slice will include all items up to, but not including, this index.- ‘step’ (optional) - The amount by which the index increases; defaults to 1.
If the step is negative, you can think of it as slicing from right to left instead of the usual left to right.
- ‘start’ (optional) - The starting index of the slice. It defaults to 0 if not provided.- ‘stop’ - The ending index (exclusive) of the slice. The slice will include all items up to, but not including, this index.- ‘step’ (optional) - The amount by which the index increases; defaults to 1.
If the step is negative, you can think of it as slicing from right to left instead of the usual left to right.
Here are some examples:

Slicing can also be used to create a shallow copy of the entire sequence by omitting both ‘start’ and ‘stop’ indices:
 Slicing is a very powerful feature of Python that allows for concise and readable manipulation of sequence data types.
Slicing is a very powerful feature of Python that allows for concise and readable manipulation of sequence data types.
Question: Can you please explain, if i want my Python script executable on Unix platform, how can i do that?
Answer: To make a Python script executable on a Unix platform, you would follow these steps:
Add a Shebang Line: At the very top of your Python script, add a line that tells the Unix system what interpreter to use to run the file. For Python, this will typically look like ‘#!/usr/bin/env python3’ for Python 3 or ‘#!/usr/bin/env python’ for Python 2.
Please see Example below:

Make the Script Executable: Change the permissions of the script file to make it executable. You can use the ‘chmod’ command in the terminal to do this.

Execute the Script Directly: Now, you can run the script directly from the command line by typing ‘./myscript. py’.
Here's a breakdown of each step:
- The shebang line (‘#!/usr/bin/env python3’) is important because it tells the system that this file should be run with the Python interpreter. It's a convention in Unix-like systems to interpret files with such a directive.- Using the ‘chmod’ command changes the file's permissions, adding the executable (‘x’) permission. The ‘+x’ indicates that you're adding the executable permission to the existing set of permissions for the file.- Running the script with ‘./’ before the file name indicates to the Unix system that you want to execute a file in the current directory, rather than looking for it in the system path.By following these steps, you make your Python script self-contained and directly runnable like a binary executable or a script in other scripting languages such as Bash.
Question: Can you please explain scope resolution in Python?
Answer: In Python, scope resolution is governed by the LEGB rule, which stands for Local, Enclosing, Global, and Built-in scopes. Here's how Python searches these scopes in order to resolve names to objects:
- Local (L): This is the innermost scope. It includes local names defined in a function. Variables that are assigned within a function are considered local to that function.
- Enclosing (E): This scope covers the outer function in case you have nested functions. If a name is not found in the local scope, Python then looks in the nearest enclosing scope (the function containing the current function).
- Global (G): If Python can’t find the name in the local and enclosing scopes, it looks for it in the global scope, which is the module in which the code is being executed.
- Built-in (B): This is the outermost scope. If a name is not found in all the previously mentioned scopes, Python will check if it’s a built-in name. These names are preassigned in Python and include functions like ‘print()’ and ‘id()’.
Here's an example that demonstrates scope resolution:

When you run this code, the output will be:
 Python resolves the name ‘x’ in the ‘inner()’ function by looking into the local scope first.
When called in the ‘outer()’ function, it finds ‘x’ in the enclosing scope. And outside of any functions, it finds ‘x’ in the global scope. If you need to modify a global variable within a function, you can use the ‘global’ keyword to declare that you want to work with the global scope. Similarly, the ‘nonlocal’ keyword is used to work with variables in enclosing scopes.
Python resolves the name ‘x’ in the ‘inner()’ function by looking into the local scope first.
When called in the ‘outer()’ function, it finds ‘x’ in the enclosing scope. And outside of any functions, it finds ‘x’ in the global scope. If you need to modify a global variable within a function, you can use the ‘global’ keyword to declare that you want to work with the global scope. Similarly, the ‘nonlocal’ keyword is used to work with variables in enclosing scopes.
Question: Please explain Dict and List comprehension in Python?
Answer: Dict and list comprehensions in Python provide a concise way to create lists and dictionaries without the need for a verbose for loop. They follow the form of ‘[expression for item in iterable]’ for lists and ‘{key: value for item in iterable}’ for dictionaries.
List Comprehension: It's used to create a new list by applying an expression to each item in an iterable (like a list or a range).
For example, if we want to create a list of squares, instead of using a loop:

We can write:

You can also add conditions to list comprehensions:

Dict Comprehension: Similarly, a dictionary comprehension creates a dictionary from an iterable. The syntax includes curly braces containing a key-value pair followed by a for clause:
 This creates a dictionary where the keys are numbers from 0 to 9, and the values are their squares.
This creates a dictionary where the keys are numbers from 0 to 9, and the values are their squares.
Just like list comprehensions, dict comprehensions can also have conditional logic:
 This will create a dictionary with squares of even numbers only. Using comprehensions makes code shorter and often easier to read. However, they should be used judiciously to ensure that the readability of the code is not compromised, especially for more complex expressions or conditions.
This will create a dictionary with squares of even numbers only. Using comprehensions makes code shorter and often easier to read. However, they should be used judiciously to ensure that the readability of the code is not compromised, especially for more complex expressions or conditions.
Question: Would you able to explain Lambda in Python, with example?
Answer: In Python, a lambda function is a small anonymous function defined with the ‘lambda’ keyword. Unlike a normal ‘def’-defined function, a lambda function is a single expression that evaluates and returns a value. It's often used in places where you need a simple function for a short period of time, and you're interested in getting the job done without the overhead of a full function definition.
Here's the syntax of a lambda function:

And here's a simple example of a lambda function that adds two numbers:
 Lambda functions can take any number of arguments, but they can only have one expression. They are often used with functions like ‘filter()’, ‘map()’, and ‘reduce()’ which expect a function object as one of their arguments.
Lambda functions can take any number of arguments, but they can only have one expression. They are often used with functions like ‘filter()’, ‘map()’, and ‘reduce()’ which expect a function object as one of their arguments.
Here’s an example of using ‘map()’ with a lambda:
 In this case, the lambda function is used to square each number in the ‘numbers’ list. The ‘map()’ function applies the lambda to each element of the list, and the result is a new list with the squared values.
In this case, the lambda function is used to square each number in the ‘numbers’ list. The ‘map()’ function applies the lambda to each element of the list, and the result is a new list with the squared values.
Question: If you want to copy an object, how would you do the same?
Answer: In Python, copying an object can be done in a couple of ways, depending on whether a shallow copy or a deep copy is needed. Shallow Copy: A shallow copy creates a new object but does not create copies of nested objects within the original object. It only copies the reference pointers to the nested objects. You can create a shallow copy using the ‘copy’ module's ‘copy()’ function.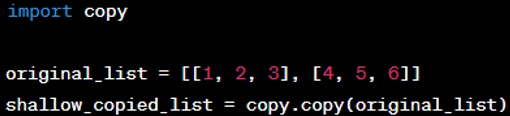 In this case, ‘shallow copied list’ is a new outer list, but the inner lists are still references to the original lists.
In this case, ‘shallow copied list’ is a new outer list, but the inner lists are still references to the original lists.
Deep Copy: A deep copy creates a new object and recursively copies all objects found within the original object. To perform a deep copy, you would use the ‘copy’ module's ‘deepcopy()’ function.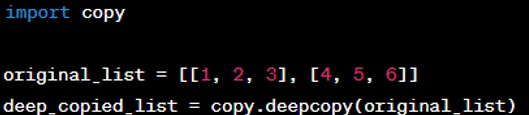 Now, ‘deep copied list’ is a completely independent copy of ‘original list’, including all inner lists.The choice between shallow and deep copying depends on the context and the needs of the program. For simple objects without nested structures, a shallow copy is often sufficient.
For complex objects with nested structures, a deep copy is typically necessary to ensure that independent copies of all nested objects are made.
Now, ‘deep copied list’ is a completely independent copy of ‘original list’, including all inner lists.The choice between shallow and deep copying depends on the context and the needs of the program. For simple objects without nested structures, a shallow copy is often sufficient.
For complex objects with nested structures, a deep copy is typically necessary to ensure that independent copies of all nested objects are made.
Question: Can you please explain xrange and range in Python?
Answer: xrange and range are both used to generate a sequence of numbers in Python. However, they are available in different versions of Python and have distinctions in their behavior and performance.
In Python 2:
- ‘range()’ returns a list of numbers created on demand, consuming memory proportional to the range's size. For example, ‘range(0, 3)’ would produce the list ‘[0, 1, 2]’.- ‘xrange()’, on the other hand, returns an xrange object that generates the numbers on demand (a type of lazy evaluation). It is more memory efficient, especially for large ranges, as it yields one number at a time in a loop, rather than storing the entire sequence in memory.
In Python 3:
- ‘range()’ behaves like ‘xrange()’ from Python 2, offering a more memory-efficient, lazy evaluation iterator. The ‘xrange()’ function has been removed, so ‘range()’ is the only option and it behaves efficiently.Hence, if you're using Python 2, you would use ‘xrange()’ for large loops for better performance. In Python 3, you would just use ‘range()’, as it now incorporates the same lazy evaluation functionality that ‘xrange()’ provided in Python 2.
Question: Please explain pickling and unpickling?
Answer: Pickling is the process of converting a Python object into a byte stream. This byte stream can be stored as a file or sent over a network and then reconstructed back into the original object by a process known as unpickling.
Here's a brief explanation of both:
Pickling (Serialization):
- What it does: It serializes Python objects to a byte representation that can be saved to disk or transmitted over a network.
- How it's used: The ‘pickle’ module in Python is used for this. You'd use ‘pickle.dump()’ if you want to write a pickled object to a file, or ‘pickle.dumps()’ to obtain the pickled byte stream.
Unpickling (Deserialization):
- What it does: It takes a byte stream (from a binary file or bytes-like object) and converts it back into a Python object.
- How it's used: Corresponding to the methods for pickling, ‘pickle.load()’ is used to read a pickled object from a file, and ‘pickle.loads()’ is used to load an object from a byte stream.
Example of pickling and unpickling:
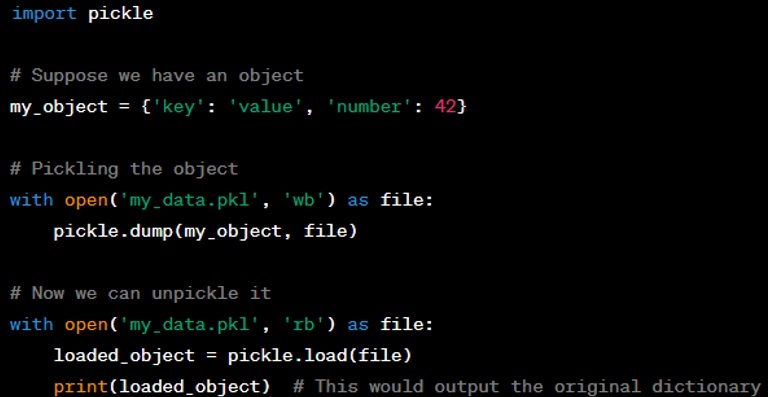
Note for an Interview Setting: While pickling is powerful, it's important to mention that it should be used cautiously:
- Security Risk: Unpickling data received from an untrusted source can be a security risk, as it may execute arbitrary code during the unpickling process.
- Compatibility: Pickle files are not guaranteed to be compatible across different versions of Python.
- Alternatives: For these reasons, other serialization formats like JSON or XML are often preferred for data exchange between different systems or languages.
If you're discussing this in an interview, you might be expected to know about these risks and alternatives.
Question: What is the difference between .py and .pyc files?
Answer: In Python, ‘.py’ files are the source code files containing the Python code, while ‘.pyc’ files are the compiled bytecode files that the Python interpreter generates.
When you write a Python program, you typically save the code in a ‘.py’ file. This file contains human-readable code that you have written. When you run the program, the Python interpreter compiles the ‘.py’ file into a ‘.pyc’ file which contains bytecode. Bytecode is a low-level set of instructions that the Python interpreter can execute. The generation of ‘.pyc’ files is an intermediate step that Python takes to execute the programs faster. When you run the Python program the next time, if the ‘.py’ file hasn't changed, the Python interpreter will load the bytecode from the ‘.pyc’ file directly, which is faster than recompiling the source code from the ‘.py’ file.The ‘.pyc’ files are typically stored in a ‘ pycache ’ directory, and they are platform-independent, which means you can run them on any machine that has a compatible Python interpreter, regardless of its operating system. In a nutshell, the ‘.py’ file is your code, and the ‘.pyc’ file is the compiled version of your code that Python uses to run the program more efficiently.
Chapter-2: Interview Question for Python Fundamental Part 2.
Question: What are the benefits of using Python language compare to existing other programming language?
Answer: Python offers several benefits that make it a popular choice among developers:
- Readability and Simplicity: Python's syntax is clear and intuitive, making it an excellent language for beginners and a swift tool for experienced developers to translate thoughts into working code.
- Rapid Development: Its high-level data structures, along with dynamic typing and binding, facilitate rapid application development.
- Extensive Standard Library: Python's comprehensive standard library provides modules and functions for a wide variety of tasks, reducing the need for third-party tools.
- Interoperability: Python can interact with other languages and platforms via libraries, and it's widely supported across operating systems.
- Versatility: It's used in various domains, from web development to data analysis, machine learning, and scientific computing.
- Flexibility: Python supports multiple programming paradigms, including procedural, object-oriented, and functional programming.
- Integrated Development Environments (IDEs): Python's support for numerous IDEs, like PyCharm and VS Code, allows for powerful coding, debugging, and testing environments.
- Open Source: It's free to use and distribute, even for commercial purposes, which can significantly reduce development costs.
- By focusing on these technical aspects, Python positions itself as an adaptable and efficient choice for a wide range of programming tasks.
Question: What is a dynamically typed and static typed language?
Answer: In programming languages, the distinction between dynamically typed and statically typed languages pertains to when the type checking is performed and how variable types are assigned.
Dynamically Typed Languages:
- Type Checking: In dynamically typed languages, type checking is performed at runtime. This means that you don't have to explicitly declare the type of a variable when you write code. The type of a variable is determined at the moment the code is executed, which allows for more flexibility.
- Flexibility: They are generally more flexible in terms of coding, as you can assign different types of data to the same variable at different points in the program.
- Example Languages: Python, Ruby, JavaScript, and PHP are examples of dynamically typed languages.
Statically Typed Languages:
- Type Checking: Statically typed languages require the type of all variables to be explicitly declared and determined at compile-time, before the program is run. This can catch type errors early in the development process.
- Performance: Statically typed languages can be more efficient at runtime because the compiler knows the exact data types that are used and can optimize the execution.
- Example Languages: C, C++, Java, and Swift are examples of statically typed languages.
The key difference is that in dynamically typed languages, the types are associated with run-time values and not named variables/expressions themselves, whereas in statically typed languages, the types are associated with variables/expressions themselves and need to be known at compile-time.
Question: What do you mean by an Interpreted language and in context of Python?
Answer: An interpreted language is a type of programming language for which most of its implementations execute instructions directly and freely, without previously compiling a program into machine-language instructions. The interpreter executes the program directly, translating each statement into a sequence of one or more subroutines and then into another language (often machine code).
In the context of Python: Python is often referred to as an interpreted language because Python code is executed by an interpreter. The standard Python implementation, CPython, compiles Python code into bytecode (which is a low-level set of instructions that is then executed by an interpreter). However, this compiled form is not in the machine language of any computer. The Python interpreter reads this bytecode and translates it into the appropriate machine code for execution.
Here are some characteristics of Python as an interpreted language:
- Ease of Use and Flexibility: Since the code is not compiled before execution, developers can write and test small pieces of code very quickly, which is useful for prototyping and experimental development.
- Portability: Python programs can run on any machine with a compatible interpreter, making Python code platform-independent as long as the interpreter is present.
- Runtime Evaluation: Python can evaluate and execute code at runtime, allowing for dynamic typing, reflection, and introspection, as well as the construction and evaluation of code on-the-fly. However, this interpretation layer can make Python programs run slower than equivalent programs in compiled languages, such as C or C++. To mitigate this, various implementations of Python may use Just-In-Time (JIT) compilation, such as PyPy, to improve execution speeds.
Question: What is PEP 8 and why is it important?
Answer: PEP 8, also known as the Python Enhancement Proposal 8, is the style guide for writing Python code. It was written in 2001. The PEP 8 document provides conventions for the formatting of Python code. This includes guidelines on how to name variables, how to indent your code, how to structure your import statements, and more. The overarching goal of PEP 8 is to improve the readability and consistency of Python code.
PEP 8 is important because:
- Readability: Since Python emphasizes readability, a common style guide helps maintain a uniform style of coding, making it easier to understand the code written by different authors.
- Maintainability: Consistent coding style makes it easier to maintain and update code, which is especially important in collaborative projects or when codebases are handed over to new developers.
- Community Standards: PEP 8 represents a set of rules endorsed by the Python community, which helps in setting a standard that Python developers can adhere to.
- Quality and Productivity: Following PEP 8 can lead to more reliable and maintainable code. It can also increase productivity, as developers spend less time deciphering the styling of the code and more on understanding the logic and implementation.
- Tooling Support: Many development tools, linters, and IDEs have support for PEP 8, providing features like real-time linting and auto-formatting to help developers stick to these guidelines. While PEP 8 is a recommendation and not a compulsory standard, adhering to it is considered good practice in the Python community. It allows programmers to focus on writing code rather than on the layout, and ensures that the large body of Python code available in open-source projects is more or less uniformly styled.
Question: Can you please explain the Scope in Python and how it is impacted. Please give example?
Answer: In Python, scope refers to the region in a program where a namespace is directly accessible. In other words, scope determines the visibility of a variable within the code. The two basic scopes in Python are:
- Local Scope: Refers to variables defined within a function. These variables are only accessible within that function and not outside of it.
- Global Scope: Refers to variables defined outside of a function. These variables are accessible anywhere within the script.
The concept of scope is impacted by where you declare a variable. The LEGB rule is an acronym used to describe the scope resolution process in Python:
- L, Local — Names assigned in any way within a function (‘def’ or ‘lambda’), and not declared global in that function. - E, Enclosing-function locals — Names in the local scope of any and all statically enclosing functions (‘def’ or ‘lambda’), from inner to outer.- G, Global (module) — Names assigned at the top-level of a module file, or declared global in a ‘def’ within the file.
- B, Built-in (Python) — Names preassigned in the built-in names module: ‘open’, ‘range’, ‘SyntaxError’, etc.
Here's an example illustrating local and global scope:
Output you can see as below:
In this example, there are two different ‘x’ variables: one in the global scope (outside the function) and one in the local scope (inside the function). When you print ‘x’ inside ‘my function()’, it prints ‘local’ because the function scope takes precedence. Outside the function, it prints ‘global’ because there is no local scope.
Here is an example that shows how an enclosed function can impact scope:
Output you can see as below:
Question: Can you please explain the difference between list and tuples?
Answer: Certainly! Lists and tuples are both sequence types in Python that can be used to store collections of items. Here are the key differences between them:
Mutability:
- List: Lists are mutable, which means that you can change, add, or remove items after the list has been created.
- Tuple: Tuples are immutable; once a tuple is created, you cannot change, add, or remove items from it.
Syntax:
- List: A list is defined by square brackets ‘[]’.
- Tuple: A tuple is defined by parentheses ‘()’.
Performance:
- List: Lists have a variable size, so they require more memory and incur a greater performance cost for operations like copying, iteration, and deletion.
- Tuple: Tuples have a fixed size and are generally faster than lists when it comes to iteration and have a smaller memory overhead due to their immutability.
Use Cases:
- List: Use a list when you have a collection of items that may change over time, and you need to manipulate the contents of that collection.
- Tuple: Tuples are commonly used for small collections of values that will not need to change, such as the coordinates of a point in 2D space.
Methods:
- List: Lists support several methods that allow you to modify the list, such as ‘append()’, ‘remove()’, ‘pop()’, ‘insert()’, and more.
- Tuple: Tuples do not have methods for adding or removing items. They do, however, support methods for finding elements (‘index()’) and counting occurrences (‘count()’), which do not modify the tuple.
Here is a simple example to illustrate both:
Question: Can you please explain pass in Python?
Answer: In Python, ‘pass’ is a statement that serves as a placeholder or a no-operation (no-op); nothing happens when it is executed. It is used when a statement is required syntactically but you do not want any command or code to be executed.
The ‘pass’ statement is commonly used:
As a placeholder for future code. When writing new code, you might use ‘pass’ to indicate a block where code will eventually go, but has not been written yet.
Please see Example below:
Please see Example below:
Please see Example below:
Please see Example below:
Question: Can you please explain global, protected and private attributes in Python?
Answer: In Python, the concept of access modifiers like private, protected, and public—as found in some other object-oriented languages—is not enforced by the language itself. However, there is a convention used by Python developers to denote private and protected attributes, using underscores as a prefix.
Here are how these concepts are generally applied in Python:
Public Attributes: By default, all attributes of a class are public, which means they can be accessed from outside the class.
Protected Attributes: These are attributes that are intended to be used only within the base class and its derived classes. By convention, a single underscore ‘ ’ is used as a prefix to the attribute name to indicate that it is a protected member.
Please see Example below:
Private Attributes: These are attributes that should not be accessed from outside the class. In Python, double underscores ‘ ’ are used at the beginning of the attribute name to "name mangle" it, which means that the interpreter changes the name of the variable in a way that makes it harder to create subclasses that accidentally override private attributes and methods.
Please see Example below:
Question: Please explain continue, break and pass in Python?
Answer: In Python, ‘continue’, ‘break’, and ‘pass’ are control statements that alter the flow of a typical loop. Here's a brief explanation of each:
continue: The ‘continue’ statement immediately stops the current iteration of the loop and moves control back to the top of the loop for the next iteration. It's commonly used to skip over certain elements or conditions within a loop.
Please see Example below:
break: The ‘break’ statement is used to exit or "break out" of a loop, regardless of the loop’s normal control structure. It can be used in both ‘while’ and ‘for’ loops. When a ‘break’ is encountered, the loop is terminated immediately, and program control resumes at the next statement following the loop.
Please see Example below:
pass: The ‘pass’ statement does nothing and is used as a placeholder in places where your code will eventually go, but has not been written yet (e.g., in stub functions or classes). It allows you to handle the condition without the loop being impacted in any way. It’s typically used for creating minimal classes or functions to keep the interpreter happy when it expects an indented block.
Please see Example below:
Question: Please explain unit test concept in Python?
Answer: Unit testing is a software testing method where individual units or components of a software application are tested in isolation from the rest of the application. The purpose of unit testing is to validate that each unit of the software performs as designed. A unit is the smallest testable part of any software and usually has one or a few inputs and usually a single output.
In the context of Python, unit testing can be carried out using the ‘unittest’ module, which is included in Python's standard library. Here’s a brief explanation of how you would use it:
Writing Test Cases: You create a subclass of ‘unittest.TestCase’, and then define test methods within this subclass. Each test method should test a specific aspect of the behavior of the code you are writing tests for.
Please see Example below:
Assertions: ‘unittest’ provides a set of assertion methods that can be used to check for various conditions, such as equality, truthiness, or exceptions being raised.
Running Tests: You can run tests by calling ‘unittest.main()’. This runs the test runner by discovering all classes that inherit from ‘unittest.TestCase’ in the current module.
Setup and Teardown: ‘unittest.TestCase’ provides ‘setUp’ and ‘tearDown’ methods that you can override to provide instructions that will be executed before and after each test method, respectively.
Question: Please explain docstring in Python?
Answer: In Python, a docstring is a string literal that occurs as the first statement in a module, function, class, or method definition. A docstring becomes the ‘ doc ’ special attribute of that object. They're used to explain what the object does, its parameters, return value, and any other important details.
Docstrings are enclosed within triple quotes (‘"""‘ or ‘'''‘), allowing for multi-line descriptions. Here's how they're used in various parts of the code:
Module Docstrings:
At the beginning of a Python file, you might see a docstring that explains what the module contains or its purpose.
Function and Method Docstrings:
Below the ‘def’ line of a function or method, the docstring describes what the function/method does, its parameters, its return value, and any other relevant information.
Class Docstrings:
Right after the class definition, the docstring might explain the purpose of the class and its behavior.
Importance:
Docstrings are important for several reasons:
- Documentation: They are a built-in way of associating documentation with Python code. Tools like Sphinx can auto-generate documentation from docstrings.
- Readability: They improve code readability by providing developers with a quick way to understand what a piece of code is supposed to do without having to read and interpret the logic.
- Introspection: They can be accessed at runtime using the ‘. doc ’ attribute, which is useful for introspection. This feature facilitates practices such as automatic help-text generation and testing.Adherence to proper docstring conventions is considered good practice in Python, and PEP 257 provides a more comprehensive guide on how to write docstrings.
Question: Can you please explain slicing concept in Python with example?
Answer: Slicing in Python refers to the technique of accessing a range or a subsequence of elements from a sequence type, such as lists, strings, tuples, and others. Slicing is done by specifying a start index and a stop index, as well as an optional step index, using a colon ‘:’ to separate them inside square brackets ‘[]’.
The general form of slicing is:
Here are some examples:
Slicing can also be used to create a shallow copy of the entire sequence by omitting both ‘start’ and ‘stop’ indices:
Question: Can you please explain, if i want my Python script executable on Unix platform, how can i do that?
Answer: To make a Python script executable on a Unix platform, you would follow these steps:
Add a Shebang Line: At the very top of your Python script, add a line that tells the Unix system what interpreter to use to run the file. For Python, this will typically look like ‘#!/usr/bin/env python3’ for Python 3 or ‘#!/usr/bin/env python’ for Python 2.
Please see Example below:
Make the Script Executable: Change the permissions of the script file to make it executable. You can use the ‘chmod’ command in the terminal to do this.
Execute the Script Directly: Now, you can run the script directly from the command line by typing ‘./myscript. py’.
Here's a breakdown of each step:
- The shebang line (‘#!/usr/bin/env python3’) is important because it tells the system that this file should be run with the Python interpreter. It's a convention in Unix-like systems to interpret files with such a directive.- Using the ‘chmod’ command changes the file's permissions, adding the executable (‘x’) permission. The ‘+x’ indicates that you're adding the executable permission to the existing set of permissions for the file.- Running the script with ‘./’ before the file name indicates to the Unix system that you want to execute a file in the current directory, rather than looking for it in the system path.By following these steps, you make your Python script self-contained and directly runnable like a binary executable or a script in other scripting languages such as Bash.
Question: Can you please explain scope resolution in Python?
Answer: In Python, scope resolution is governed by the LEGB rule, which stands for Local, Enclosing, Global, and Built-in scopes. Here's how Python searches these scopes in order to resolve names to objects:
- Local (L): This is the innermost scope. It includes local names defined in a function. Variables that are assigned within a function are considered local to that function.
- Enclosing (E): This scope covers the outer function in case you have nested functions. If a name is not found in the local scope, Python then looks in the nearest enclosing scope (the function containing the current function).
- Global (G): If Python can’t find the name in the local and enclosing scopes, it looks for it in the global scope, which is the module in which the code is being executed.
- Built-in (B): This is the outermost scope. If a name is not found in all the previously mentioned scopes, Python will check if it’s a built-in name. These names are preassigned in Python and include functions like ‘print()’ and ‘id()’.
Here's an example that demonstrates scope resolution:
When you run this code, the output will be:
Question: Please explain Dict and List comprehension in Python?
Answer: Dict and list comprehensions in Python provide a concise way to create lists and dictionaries without the need for a verbose for loop. They follow the form of ‘[expression for item in iterable]’ for lists and ‘{key: value for item in iterable}’ for dictionaries.
List Comprehension: It's used to create a new list by applying an expression to each item in an iterable (like a list or a range).
For example, if we want to create a list of squares, instead of using a loop:
We can write:
You can also add conditions to list comprehensions:
Dict Comprehension: Similarly, a dictionary comprehension creates a dictionary from an iterable. The syntax includes curly braces containing a key-value pair followed by a for clause:
Just like list comprehensions, dict comprehensions can also have conditional logic:
Question: Would you able to explain Lambda in Python, with example?
Answer: In Python, a lambda function is a small anonymous function defined with the ‘lambda’ keyword. Unlike a normal ‘def’-defined function, a lambda function is a single expression that evaluates and returns a value. It's often used in places where you need a simple function for a short period of time, and you're interested in getting the job done without the overhead of a full function definition.
Here's the syntax of a lambda function:
And here's a simple example of a lambda function that adds two numbers:
Here’s an example of using ‘map()’ with a lambda:
Question: If you want to copy an object, how would you do the same?
Answer: In Python, copying an object can be done in a couple of ways, depending on whether a shallow copy or a deep copy is needed. Shallow Copy: A shallow copy creates a new object but does not create copies of nested objects within the original object. It only copies the reference pointers to the nested objects. You can create a shallow copy using the ‘copy’ module's ‘copy()’ function.
Deep Copy: A deep copy creates a new object and recursively copies all objects found within the original object. To perform a deep copy, you would use the ‘copy’ module's ‘deepcopy()’ function.
Question: Can you please explain xrange and range in Python?
Answer: xrange and range are both used to generate a sequence of numbers in Python. However, they are available in different versions of Python and have distinctions in their behavior and performance.
In Python 2:
- ‘range()’ returns a list of numbers created on demand, consuming memory proportional to the range's size. For example, ‘range(0, 3)’ would produce the list ‘[0, 1, 2]’.- ‘xrange()’, on the other hand, returns an xrange object that generates the numbers on demand (a type of lazy evaluation). It is more memory efficient, especially for large ranges, as it yields one number at a time in a loop, rather than storing the entire sequence in memory.
In Python 3:
- ‘range()’ behaves like ‘xrange()’ from Python 2, offering a more memory-efficient, lazy evaluation iterator. The ‘xrange()’ function has been removed, so ‘range()’ is the only option and it behaves efficiently.Hence, if you're using Python 2, you would use ‘xrange()’ for large loops for better performance. In Python 3, you would just use ‘range()’, as it now incorporates the same lazy evaluation functionality that ‘xrange()’ provided in Python 2.
Question: Please explain pickling and unpickling?
Answer: Pickling is the process of converting a Python object into a byte stream. This byte stream can be stored as a file or sent over a network and then reconstructed back into the original object by a process known as unpickling.
Here's a brief explanation of both:
Pickling (Serialization):
- What it does: It serializes Python objects to a byte representation that can be saved to disk or transmitted over a network.
- How it's used: The ‘pickle’ module in Python is used for this. You'd use ‘pickle.dump()’ if you want to write a pickled object to a file, or ‘pickle.dumps()’ to obtain the pickled byte stream.
Unpickling (Deserialization):
- What it does: It takes a byte stream (from a binary file or bytes-like object) and converts it back into a Python object.
- How it's used: Corresponding to the methods for pickling, ‘pickle.load()’ is used to read a pickled object from a file, and ‘pickle.loads()’ is used to load an object from a byte stream.
Example of pickling and unpickling:
Note for an Interview Setting: While pickling is powerful, it's important to mention that it should be used cautiously:
- Security Risk: Unpickling data received from an untrusted source can be a security risk, as it may execute arbitrary code during the unpickling process.
- Compatibility: Pickle files are not guaranteed to be compatible across different versions of Python.
- Alternatives: For these reasons, other serialization formats like JSON or XML are often preferred for data exchange between different systems or languages.
If you're discussing this in an interview, you might be expected to know about these risks and alternatives.
Question: What is the difference between .py and .pyc files?
Answer: In Python, ‘.py’ files are the source code files containing the Python code, while ‘.pyc’ files are the compiled bytecode files that the Python interpreter generates.
When you write a Python program, you typically save the code in a ‘.py’ file. This file contains human-readable code that you have written. When you run the program, the Python interpreter compiles the ‘.py’ file into a ‘.pyc’ file which contains bytecode. Bytecode is a low-level set of instructions that the Python interpreter can execute. The generation of ‘.pyc’ files is an intermediate step that Python takes to execute the programs faster. When you run the Python program the next time, if the ‘.py’ file hasn't changed, the Python interpreter will load the bytecode from the ‘.pyc’ file directly, which is faster than recompiling the source code from the ‘.py’ file.The ‘.pyc’ files are typically stored in a ‘ pycache ’ directory, and they are platform-independent, which means you can run them on any machine that has a compatible Python interpreter, regardless of its operating system. In a nutshell, the ‘.py’ file is your code, and the ‘.pyc’ file is the compiled version of your code that Python uses to run the program more efficiently.
ReadioBook.com