
Chapter-6: Interview Question for Python Modules, Packages, Files.
Introduction: Welcome to ‘ReadioBook.com’ , in this chapter we are going to have interview question for "modules," "packages," and "files" which are related to how code is organized and reused.
Modules: A module in Python is a single file containing Python code. It may contain functions, classes, and variables, as well as runnable code. Modules are used to break down large programs into small manageable and organized files. For example, a file ‘math.py’ containing several mathematical functions can be considered a module named ‘math’.
Packages: A package is a collection of Python modules under a common namespace (directory). In other words, it's a directory that contains a special file named ‘ init . py’ (which may be empty) and one or more module files. This way, packages allow for a hierarchical structuring of the module namespace using dot notation. For instance, a package named ‘geometry’ could have modules ‘geometry.circle’, ‘geometry.square’, etc.
Files: In the context of Python programming, a file usually refers to a Python script (a ‘. py’ file) that contains code. It could be a module if it's meant to be imported, or it could be a script that is run directly. Python files can also be part of packages.- A Python file is a ‘.py’ script.- A Python module is a Python file that can be imported into other files or modules.- A Python package is a directory of Python modules that allows you to organize related modules into a single hierarchy.
Question: Can you explain the concept of the Python module search path and how Python determines where to look for modules to import?
Answer: The Python module search path is a list of locations that the Python interpreter searches for modules when you import them in your script. When you use an ‘import’ statement, Python searches for the specified module in the following order:
- The directory from which the input script was run or the current directory if the interpreter is being run interactively.
- The list of directories contained in the ‘PYTHONPATH’ environment variable, if it is set. This behaves like the system's ‘PATH’ environment variable, where each directory is separated by a colon (‘: ’) on Unix or a semicolon (‘;’) on Windows.
- The installation-dependent default directories, which are configured at the time Python is installed. This search path can be found in the ‘sys.path’ variable, which is a list of strings that determine the interpreter’s search path for modules.
Question: How does the ‘sys.path’ list influence module discovery and importing in Python?
Answer: The ‘sys.path’ list is critical in module discovery. When you import a module, Python scans the directories in ‘sys.path’ from the first to the last entry, stopping at the first place where it finds the module. If the module is not found, Python will raise a ‘ModuleNotFoundError’.
Question: What is the role of the ‘PYTHONPATH’ environment variable in the context of the module search path?
Answer: The ‘PYTHONPATH’ environment variable is an environmental variable that you can set to add additional directories where Python will look for modules. It's similar to ‘PATH’ for executables. When Python is started, the ‘PYTHONPATH’ environment variable is read, and the directories it contains are added to the ‘sys. path’ list.
Question: In what scenarios would you modify the module search path, and how can you do it within a Python script?
Answer: You might modify the module search path in scenarios where you want to import modules from directories that are not in the default search path, such as modules from a third-party library located in a non-standard directory or when your modules are spread across different directories. You can modify the search path within a Python script by appending the directory to ‘sys.
path’:

Question: How does Python's module search path interact with virtual environments?
Answer: When you activate a virtual environment, Python adjusts the ‘sys.path’ to include paths specific to the virtual environment. This usually means that it will add the virtual environment’s ‘site-packages’ directory at the start of ‘sys.path’. This ensures that packages installed in the virtual environment take precedence over the system-wide packages, allowing for project-specific dependencies and avoiding conflicts between different projects' dependencies.
Question: What is the difference between a module and a package in Python?
Answer: A module in Python is a single file containing Python code that can define functions, classes, and variables, as well as runnable code. It is a way to organize code in a hierarchical manner. Modules can be imported using the ‘import’ statement.
A package, on the other hand, is a directory that contains multiple Python modules. It includes a special ‘ init .py’ file to indicate to Python that it contains a package. This file can be empty or can contain code to initialize the package. Packages allow for a structured hierarchy of modules and can contain sub-packages of their own.
Question: How does Python's import system work behind the scenes when you import a module?
Answer: When you import a module, Python performs the following steps:
- Searches for the module in the directories listed in ‘sys.path’.- Once the module is found, Python compiles it into bytecode, which is a lower-level, platform-independent representation of the source code.- The bytecode is then executed to run the module's code and define its contents (functions, classes, variables, etc. ) in the namespace.If the module has already been imported earlier, Python uses the existing loaded module from the memory cache (‘sys.modules’) without re-importing it.
Question: Can you explain the role of the pycache directory and .pyc files in Python?
Answer: The ‘ pycache ’ directory is a directory that Python creates to store the compiled bytecode of modules in the form of ‘.pyc’ files. This directory is automatically created in the same directory as the corresponding module. The ‘.pyc’ files are platform-independent and are used to speed up module loading on subsequent imports. Instead of recompiling the source file, Python checks the timestamp of the ‘.pyc’ file against the source file and, if it is up-to-date, loads the bytecode directly, which is faster than interpreting the source file.
Question: What is the purpose of the if name == " main ": block in Python modules?
Answer: The ‘if name == " main ":’ block allows for a Python file to be used both as a reusable module and as a standalone script. When a module is run as the main program, the interpreter sets the ‘ name ’ variable to have a value ‘" main "‘. If the module is being imported from another module, ‘ name ’ will be set to the module's name.
Thus, the code within the ‘if name == " main ": ’ block will only run if the module is executed as the main file, making it useful for tests or code that you want to run when the file is executed as a script but not when it's imported.
Question: How can you create and distribute a Python package that includes modules and sub-packages?
Answer: To create and distribute a Python package, follow these steps:
- Organize your code into a directory structure with a top-level directory for the package and subdirectories for sub-packages, each with its own ‘ init .py’ file.- Write a ‘setup.py’ file at the top level of your package directory. This file includes information about the package such as its name, version, dependencies, and more. This is used by setuptools to package and distribute your module.
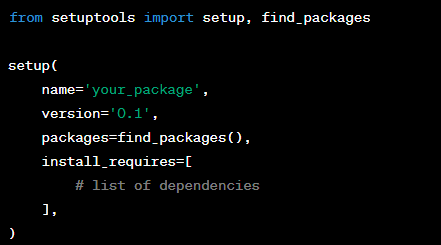
Use setuptools to create a source distribution and/or a wheel of your package:


Question: What is module reloading in Python, and why would you use it?
Answer: Module reloading in Python is the process of re-executing the module's code to update the module's namespace with any changes made to the module's source code. This is done without stopping the Python interpreter. You would use it during a long-running process like a web server or a GUI application where you want to update the code without restarting the application, which can be very helpful during development for testing changes quickly.
Question: How do you reload a module using Python's standard library?
Answer: In Python, you can reload a module using the ‘reload()’ function from the ‘importlib’ standard library module. Here's how you would do it:

Question: Can you explain any potential issues that may arise from reloading a module?
Answer: Reloading a module can cause several issues:
- State Loss: If the module had any state (such as the state of objects or variables), it will be lost as the module is re-executed.
- Singleton Objects: If there are singleton objects, they might get duplicated because the old objects still exist in the memory, and new ones are created upon reloading.
- References: Objects that were instances of classes from the module before reloading will not be instances of the new classes after reloading and may behave unpredictably.
- Dependencies: If other modules have imported names from the module being reloaded, they won't be updated automatically to reflect changes.
Question: How does Python's importlib.reload() function work under the hood?
Answer: Under the hood, ‘importlib.reload()’ function first checks the module's entry in ‘sys.modules’, then it re-executes the module's code in the existing module's namespace. This means that the re-execution will overwrite the existing definitions and add any new ones. It does not replace the old module object in ‘sys. modules’, so references to the module and its objects will remain valid, although they may now refer to outdated objects or definitions.
Question: In a long-running Python application like a web server, what considerations should be taken when reloading a module?
Answer: In a long-running application like a web server, consider the following when reloading a module:
- Thread Safety: Ensure that reloading is done in a thread-safe manner to prevent concurrent access to partially reloaded modules.
- Consistency: Ensure that all parts of the application are consistent with respect to the reloaded module. You may need to update references in other modules or parts of the application.
- Memory Leaks: Be aware that reloading might introduce memory leaks if references to old objects are kept around.
- Testing: Thoroughly test the application after reloading to make sure that changes have been applied as expected without side effects.
- Downtime: Plan the reload to occur at a time that minimizes impact on users, as there may be a brief period when the system is not fully operational.
Question: What is the difference between a Python module and a package?
Answer: A Python module is a single file containing Python definitions and statements. A module can define functions, classes, and variables. A Python package, however, is a way of organizing related modules into a directory hierarchy. It contains a collection of modules and an ‘ init .py’ file in each directory of the hierarchy to tell Python that the directory should be treated as a package or a sub-package.
Question: How do you install a package in Python?
Answer: You can install a package in Python using the ‘pip’ tool, which is the package installer for Python. To install a package, you use the following command in your terminal or command prompt:

Question: Can you explain the use of the init .py file in Python packages?
Answer: The ‘ init .py’ file is used to initialize a Python package. It can execute package initialization code or set up the ‘ all ’ variable to control which modules the package exports as the API, while keeping other modules as internal. It also serves as a signal to Python that the directory it is in should be treated as a package. This file can be empty but must be present in the directory.
Question: How can you create your own Python package?
Answer: To create your own Python package, follow these steps:
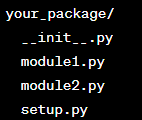
- Create a directory for your package and give it a package name.- Within this directory, place your modules (Python files).- Add an ‘ init .py’ file to the directory.- Optionally, include a ‘setup.py’ file at the top level to make it distributable via ‘pip’.
Here's a simple directory structure for a package:
Question: What is the purpose of pip in Python and how does it differ from conda?
Answer: ‘pip’ is a package manager for Python that allows you to install and manage additional libraries that are not part of the Python standard library. ‘pip’ works with PyPI (Python Package Index) to manage packages.
‘conda’ is a package manager like ‘pip’, but it is also an environment manager. It can be used to install Python packages, but it also works with packages in other programming languages, and it allows you to create isolated environments that have their own sets of packages and dependencies. ‘conda’ is typically used in data science and scientific computing where complex package dependencies exist that go beyond what ‘pip’ can handle. It is part of the Anaconda distribution which includes a wide range of packages geared towards scientific computation.
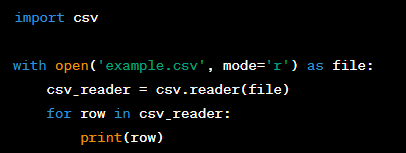
Question: How can you read and parse a CSV file in Python?
Answer: In Python, you can read and parse a CSV file using the ‘csv’ module. You would typically start by importing the module and then using the ‘csv.reader()’ function to read the file. Here's an example of how to do this:
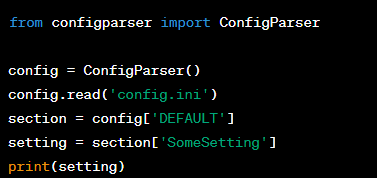
Question: What is the configparser module and how is it used to manage configuration settings in a Python application?
Answer: The ‘configparser’ module in Python is used for working with configuration files. It allows you to write Python programs which can be customized by end users easily. Configuration files are usually written in INI format. Here is an example of how you might use ‘configparser’:
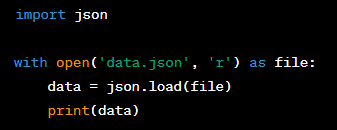
Question: How can you read JSON data from a file and convert it to a Python object?
Answer: You can read JSON data and convert it to a Python object using the ‘json’ module. The ‘json.load()’ function is used to read from a file object, parse the JSON data, and return a Python object (like a dictionary). Here is a simple example:
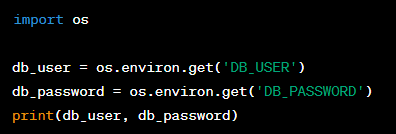
Question: What are environment variables and how can you access and use them in a Python script?
Answer: Environment variables are variables that are set outside of a program, typically through functionality built into the operating system or container, and affect how the program runs. In Python, you can access environment variables through the ‘os’ module, using ‘os.environ’ which is a dictionary that holds all the environment variables as keys and their values.
Here is an example:
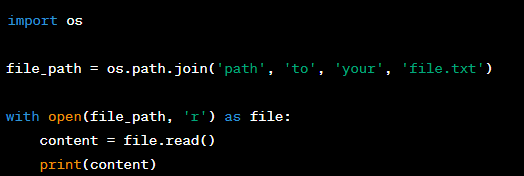
Question: Describe how you would use the os module to read a text file's contents into a Python program.
Answer: To read a text file's contents into a Python program using the ‘os’ module, you would actually combine it with the built-in ‘open()’ function. While ‘os’ provides many file-related operations, reading file content is typically done with ‘open()’. Here's an example:
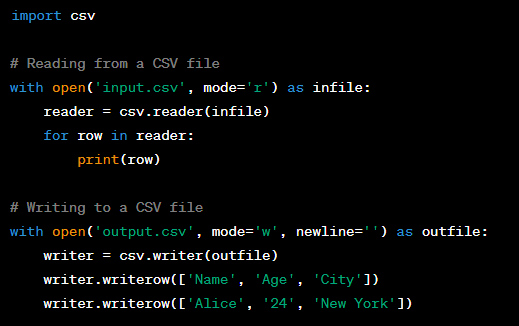
Question: How do you read and write data to a CSV file in Python?
Answer: Reading from and writing to CSV files in Python can be done using the ‘csv’ module. For reading data, you use ‘csv.reader()’ to create a reader object, and for writing data, you use ‘csv.writer()’ to create a writer object. Here's an example of both:
Question: Can you explain the difference between the 'rb' and 'wb' modes when opening a file in Python?
Answer: In Python, 'rb' and 'wb' are file modes for reading and writing in binary format. 'rb' is 'read binary', and 'wb' is 'write binary'. When you open a file in binary mode, data is read or written in the form of bytes objects. This is important for non-text files like images or videos, but can also be useful with text files to avoid encoding issues.
Question: How would you handle large files in Python without loading the entire file into memory?
Answer: To handle large files, you should read the file in chunks or line by line. This way, you never have the entire file in memory. The following example demonstrates reading a large file line by line:

Question: What is the use of the with statement when working with files in Python?
Answer: The ‘with’ statement simplifies exception handling by encapsulating common preparation and cleanup tasks in so-called context managers. For files, it ensures that the file is properly closed after its suite finishes, even if an exception is raised. This is a good practice to prevent file corruption or leaks.
Question: How do you detect and handle file encoding issues when reading a text file in Python?
Answer: File encoding issues can be detected by specifying the correct encoding when opening a file. If you're unsure of a file's encoding, you can attempt to open it with a standard encoding and handle any exceptions by trying alternative encodings. Here's an example:
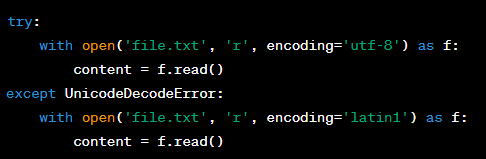

Question: How can you read input from the user in a Python program, and what function would you use?
Answer: In Python, you can read input from the user using the ‘input()’ function. This function pauses the program and waits for the user to type something into the console. Once the user presses Enter, the function returns the input as a string. Here's a simple example:

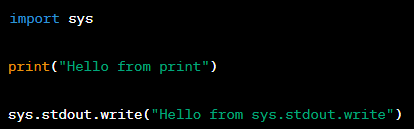
Question: In Python, what are the differences between the print() function and the sys.stdout.write() method?
Answer: The ‘print()’ function in Python is a built-in function that prints the specified message to the console, followed by a newline character by default. On the other hand, ‘sys.stdout.write()’ is a method that allows you to write a string to the standard output stream without a newline character automatically added.
‘print()’ is more convenient for simple tasks, while ‘sys.stdout.write()’ gives you more control over the output formatting. Here's an example of both:
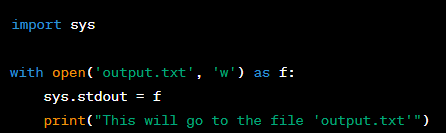
Question: How would you redirect standard output to a file in Python?
Answer: You can redirect standard output to a file in Python by overriding ‘sys.stdout’ with a file object. Here's an example:
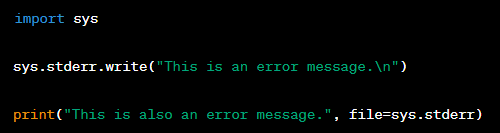
Question: Can you explain what the standard error (stderr) stream is used for in Python, and how would you write a message to it?
Answer: The standard error (‘stderr’) stream is used to output error messages and diagnostics. It is separate from the standard output (‘stdout’) and is typically displayed on the screen. To write to ‘stderr’, you can use the ‘sys.stderr.write()’ method or ‘print()’ function with the ‘file’ parameter set to ‘sys.
stderr’. Here's an example:
Question: How can you format string output in Python to include variable placeholders, and which methods or functions are available for this purpose?
Answer: Python provides several methods for string formatting to include variable placeholders. The most common ones are:
‘str.format()’: Uses curly braces ‘{}’ as placeholders.

f-Strings (formatted string literals): Introduced in Python 3.6, they allow you to embed expressions inside string literals using ‘{}’.

‘%’ operator: An older method where ‘%s’ denotes a string placeholder, ‘%d’ is for integers, etc.

Question: How does Python 3 handle Unicode and what is the default encoding for strings?
Answer: Python 3 treats all strings as Unicode by default. The default encoding for strings in Python 3 is UTF-8. This means that when you create a string, Python 3 stores it as a sequence of Unicode code points, which makes it capable of representing characters from any language.

Question: What is the difference between bytes and string objects in Python when dealing with Unicode?
Answer: In Python, string objects are sequences of Unicode code points. They represent textual data. Bytes objects, on the other hand, are sequences of bytes which represent binary data. When dealing with Unicode, you use strings to handle text and use bytes for binary data or when you need to encode a string for network transmission or file storage.
Question: How can you read and write text files containing Unicode characters in Python?
Answer: To read and write text files containing Unicode characters, you should specify the encoding when opening the file. The default encoding is UTF-8, but it can be changed if needed.
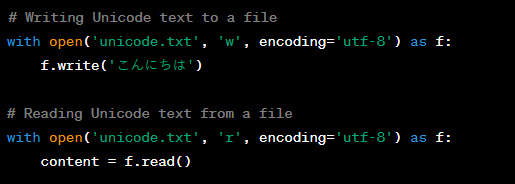
Question: Can you explain the use of the encode() and decode() methods in Python with respect to Unicode?
Answer: The ‘encode()’ method converts a string into a bytes object using a specific encoding (like UTF-8), while the ‘decode()’ method converts a bytes object back into a string using a specific encoding. These methods are used for encoding strings to bytes when you need to save text data in a binary format, or when transmitting data over the network, and for decoding bytes back to strings when reading binary data.
Question: What challenges might you face when processing files with Unicode characters and how can you overcome them in Python?
Answer: Challenges with processing files with Unicode characters include handling different encodings, dealing with Byte Order Marks (BOM), and accommodating characters that are not supported in the specified encoding. To overcome these challenges:
- Always specify the correct encoding when opening files. - Use ‘errors='ignore'‘ or ‘errors='replace'‘ in the ‘open()’ function to handle characters that can't be encoded/decoded with the given encoding.- Use libraries like ‘codecs’ to handle BOMs or rare encodings.

ReadioBook.com