
Chapter-5: Interview Question for Python Panda and NumPy.
Introduction: Welcome to ‘ReadioBook.com’ in this chapter we are going to cover pending questions of Pandas and then NumPy. NumPy, which stands for Numerical Python, is an open-source library in Python that is foundational for scientific computing in Python. It provides support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays.
Key Features of NumPy:
Efficient Storage: NumPy provides an efficient way to store and manipulate numerical data compared to Python's built-in list, which is critical for large data and computationally intensive tasks.
Vectorized Operations: NumPy arrays allow for vectorized operations, meaning operations are broadcasted across the array, which leads to concise code and faster execution.
Broadcasting: NumPy's broadcasting functionality allows arithmetic operations on arrays of different shapes, making the code cleaner and faster.
Versatile: NumPy arrays can represent various data types like integers, floats, complex numbers, and can be used for a wide variety of mathematical operations including linear algebra, statistics, and Fourier transforms.
Interoperable: NumPy is interoperable with a wide array of databases, and its array interface is widely used throughout the scientific Python ecosystem, making it an essential component for data science and machine learning.
For instance, if you're dealing with large datasets or need to perform complex mathematical computations, NumPy provides the tools you need to do that efficiently. It's often used in conjunction with libraries like Pandas for data manipulation, Matplotlib for data visualization, and SciPy for advanced scientific computing.
Question: Write a Python code snippet to create a Pandas DataFrame from a dictionary of lists.
Answer: You can create a Pandas DataFrame by importing the Pandas library and then calling the ‘DataFrame’ constructor, passing it a dictionary where keys become the column names and lists become the column data.
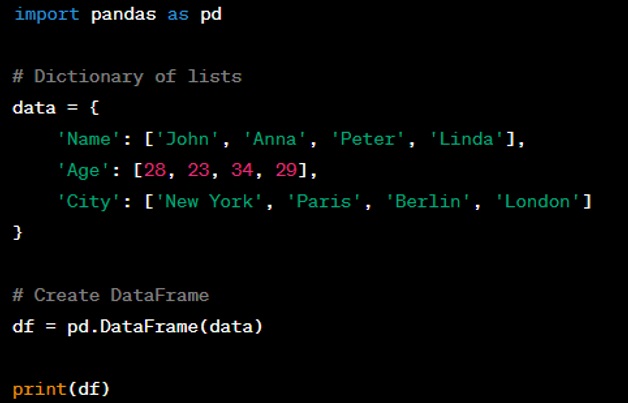
Question: How do you select a column in a DataFrame?
Answer: You can select a column in a DataFrame by using the column's name in square brackets, like ‘df['ColumnName']’, or as an attribute, like ‘df.ColumnName’ if the column name is a valid Python identifier.
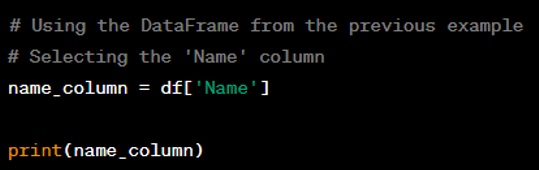
Question: Write a code sample to filter rows in a DataFrame where a column's value is greater than a specific number.
Answer: You can filter rows using a boolean condition that checks if the column's values are greater than the specified number.
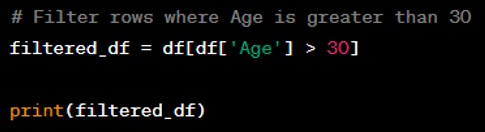
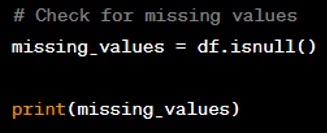
Question: Show how to check for missing values in a DataFrame.
Answer: You can check for missing values using the ‘isnull’ method, which returns a DataFrame of boolean values that are True where values are missing.
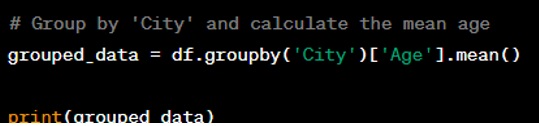
Question: Provide an example of how to use the ‘groupby’ method to aggregate data in a DataFrame.
Answer: The ‘groupby’ method is used to group data according to one or more keys and perform operations on the grouped data.
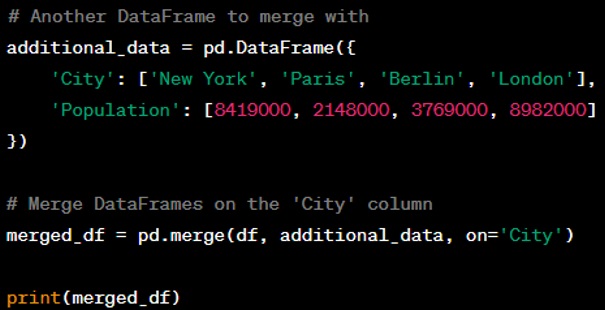
Question: Write a code example that demonstrates how to merge two DataFrames.
Answer: You can merge two DataFrames using the ‘merge’ function, which is similar to SQL joins.
Question: How would you concatenate two DataFrames vertically and horizontally?
Answer: You can use the ‘pd.concat()’ function to concatenate DataFrames. For vertical concatenation (stacking them on top of each other), you pass the DataFrames as a list to ‘pd.concat()’ without additional arguments. For horizontal concatenation (side by side), you pass the DataFrames as a list with the argument ‘axis=1’.
Vertical Concatenation:

Horizontal Concatenation:

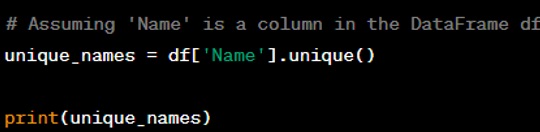
Question: Show how to find unique values in a DataFrame column.
Answer: You can use the ‘unique()’ method on a DataFrame column to get the unique values.
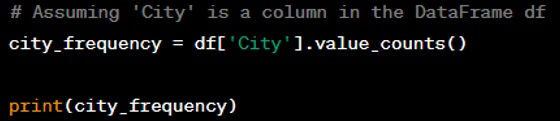
Question: Write a code snippet that returns the frequency of unique values in a DataFrame column.
Answer: To get the frequency of unique values, you can use the ‘value counts()’ method on a DataFrame column.
Question: Provide an example of creating a pivot table from a DataFrame.
Answer: A pivot table can be created using the ‘pivot table()’ function, specifying the data, index, columns, and aggregation function you want to use.
Creating a pivot table to show the average age by City and Name
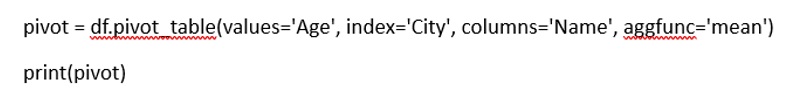
Question: How can you set a multi-index in a DataFrame?
Answer: You can set a multi-index by using the ‘set index()’ method and passing a list of columns that you want to use as indexes.
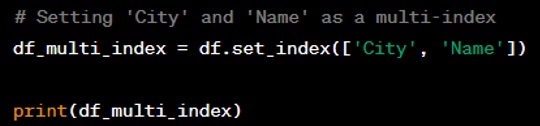
Question: Write a Python code to sort a DataFrame by multiple columns.
Answer: You can sort a DataFrame by multiple columns using the ‘sort values()’ method and providing a list of column names to the ‘by’ parameter.
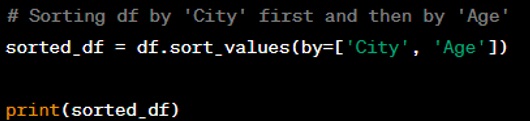
Question: Show how to apply a custom function to a DataFrame column.
Answer: You can apply a custom function to a DataFrame column using the ‘apply()’ method. Here’s an example where we define a function to double a number and then apply it to the 'Age' column.
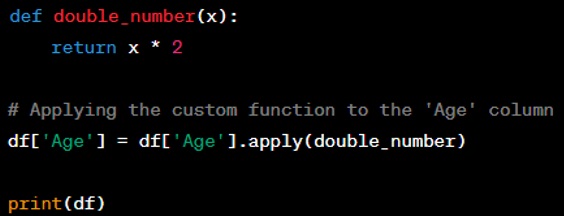
Question: Write a code snippet to parse a column of string dates into datetime objects in a DataFrame.
Answer: You can convert string dates to datetime objects using the ‘pd.to datetime()’ function.

Question: Demonstrate how to perform a vectorized string operation to split a column into multiple columns.
Answer: You can use the ‘str.split()’ method along with ‘expand=True’ to split strings in a column into separate columns.

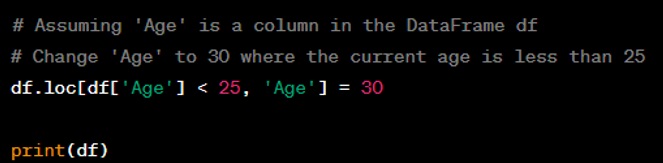
Question: How do you change the data type of a DataFrame column?
Answer: You can change the data type of a DataFrame column using the ‘astype()’ method.
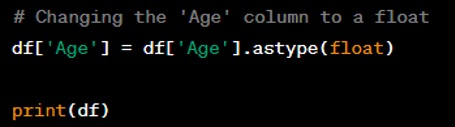
Question: Provide an example of how to replace missing values with the mean of a column in a DataFrame.
Answer: You can replace missing values with the mean of a column using the ‘fillna()’ method along with the ‘mean()’ method.
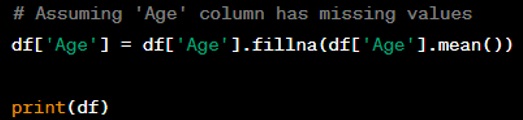
Question: Write a code snippet to rename the indexes of a DataFrame.
Answer: You can rename the indexes of a DataFrame using the ‘rename()’ method and passing a dictionary that maps old index names to new ones.
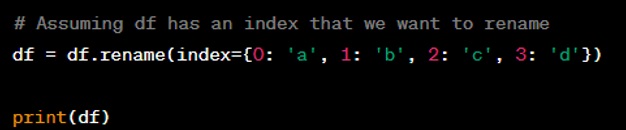
Question: Show how to change values in a DataFrame column based on a condition.
Answer: To change values in a DataFrame column based on a condition, you can use boolean indexing to identify the rows and assign a new value to them.
Question: How do you read a CSV file into a Pandas DataFrame and specify a column as the index?
Answer: You can read a CSV file into a Pandas DataFrame with the ‘read csv’ function. To specify a column as the index, you can use the ‘index col’ argument.

Question: What is NumPy, and why is it used in Python?
Answer: NumPy, which stands for Numerical Python, is an open-source library in Python that is used for scientific computing. It provides support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays. NumPy is used in Python because it offers efficient storage and better performance for mathematical operations compared to native Python lists, especially when dealing with large datasets or complex mathematical tasks. It’s a foundational library for many other scientific libraries and is widely used in data analysis, machine learning, and engineering.
Question: How do you install NumPy?
Answer: You can install NumPy using pip, which is the package installer for Python. You would simply run the following command in your command line or terminal:

Question: Can you explain what a NumPy array is and how it differs from a Python list?
Answer: A NumPy array is a grid of values, all of the same type, and is indexed by a tuple of nonnegative integers. The number of dimensions is the rank of the array, and the shape of an array is a tuple of integers giving the size of the array along each dimension. NumPy arrays are different from Python lists in several ways:
Homogeneity: NumPy arrays have homogeneous data types, meaning all elements are of the same type. In contrast, Python lists can contain elements of different types.
Performance: Operations on NumPy arrays are faster and more memory-efficient than Python lists due to NumPy’s internal implementation, which uses contiguous blocks of memory.
Functionality: NumPy comes with vectorized operations, meaning operations on arrays can be performed without explicitly writing loops. This is not the case with Python lists.
Question: How do you create a NumPy array?
Answer: You can create a NumPy array using the ‘numpy.array’ function. Here is an example:
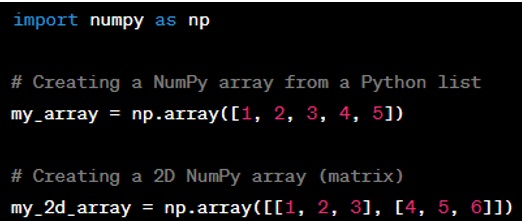
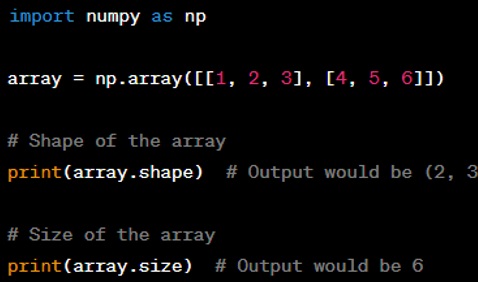
Question: How can you inspect the shape and size of a NumPy array?
Answer: You can inspect the shape of a NumPy array using the ‘.shape’ property, which returns a tuple representing the array's dimensions. The size of an array, which is the total number of elements, can be obtained using the ‘.size’ property. For example:
Question: What is broadcasting in NumPy?
Answer: Broadcasting in NumPy refers to the ability of the library to perform arithmetic operations on arrays of different shapes. When operating on two arrays, NumPy compares their shapes element-wise. It starts with the trailing dimensions and works its way forward, two dimensions are compatible when:
- They are equal, or- One of them is 1
If these conditions are not met, a ‘ValueError: operands could not be broadcast together’ exception is thrown, indicating that the arrays have incompatible shapes. The smaller array is “broadcast” across the larger array so that they have compatible shapes.
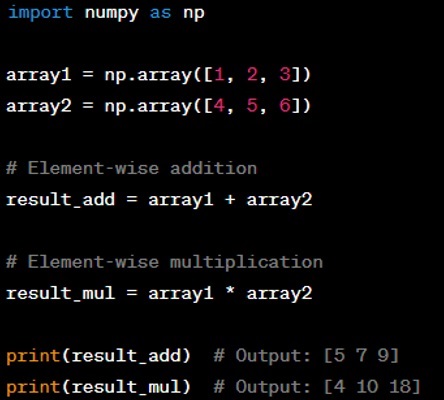
Question: How do you perform element-wise operations in NumPy?
Answer: Element-wise operations in NumPy are performed using the standard arithmetic operators (+, -, *, /, , etc.). NumPy overloads these operators to work on arrays element-wise. Here's an example:
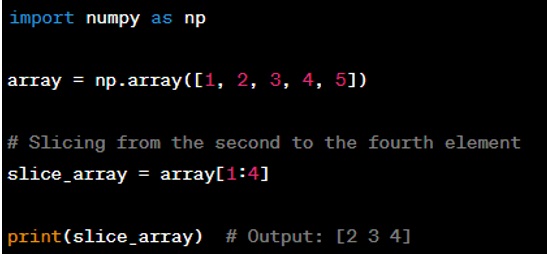
Question: Can you describe how to slice and dice a NumPy array?
Answer: Slicing in NumPy is similar to slicing lists in Python. You use the colon operator ‘:’ to slice arrays. You can specify the start, stop, and step of the slice. Here's an example:
You can also slice multi-dimensional arrays:
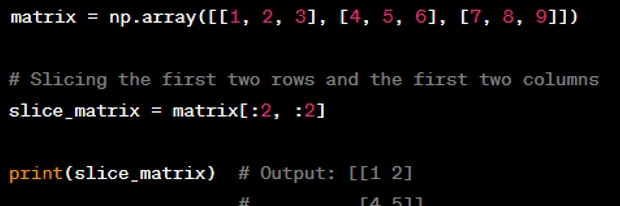
Question: What is the purpose of the ‘axis’ parameter in NumPy functions?
Answer: The ‘axis’ parameter in NumPy functions specifies the dimension along which the operation is performed. For example, if you have a 2D array and you use ‘axis=0’, the operation will be performed on columns, and if you use ‘axis=1’, the operation will be performed on rows. This is particularly useful for functions like ‘sum’, ‘mean’, ‘max’, etc.
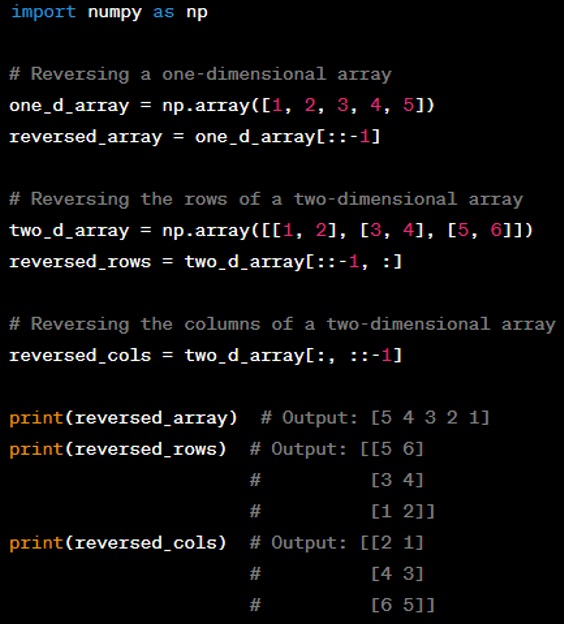
Question: How do you reverse a NumPy array?
Answer: You can reverse a NumPy array by using the slice notation with a step of ‘-1’. Here's how you can reverse a one-dimensional array and the rows or columns of a two-dimensional array:
Question: How do you handle missing data in NumPy?
Answer: In NumPy, missing data is typically represented using ‘np.nan’ for floating-point data or ‘np.ma.masked’ for a masked array that can handle data of any type. To handle missing data, you can:
- Use ‘np.isnan()’ to detect ‘np.nan’ values.- Use masked arrays (‘np.ma’) to mask out the missing or invalid entries. - Use array filtering to exclude or include data points.- Fill missing values using methods like ‘np.nanmean()’, ‘np.nanmedian()’, or ‘np.nan to num()’ which replace ‘np.nan’ with the numerical mean or median of the data, or with zero, respectively.
Question: Can you explain the difference between ‘numpy.copy()’ and ‘numpy.view()’?
Answer: ‘numpy.copy()’ returns a new array that is a deep copy of the original array. Changes to the new array do not affect the original array. On the other hand, ‘numpy.view()’ creates a new array object that looks at the same data as the original array (a shallow copy). This means that modifying the view will affect the original array since they share the same data buffer. Views are useful for operations that do not modify data, such as reshaping or broadcasting.
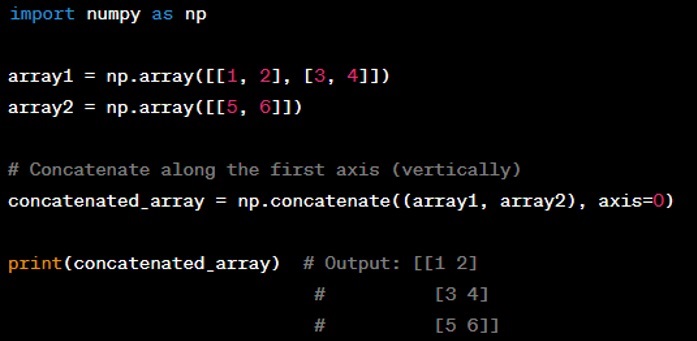
Question: How do you concatenate two or more NumPy arrays?
Answer: You can concatenate two or more NumPy arrays using the ‘np.concatenate()’ function. You need to pass a sequence of arrays that you want to concatenate along with the ‘axis’ parameter which decides the axis along which the arrays will be joined. Here's an example:
Question: How do NumPy's ‘arange’ and ‘linspace’ functions differ?
Answer: Both ‘np.arange’ and ‘np.linspace’ are used to create arrays of evenly spaced values within a defined interval. ‘np.arange’ creates arrays with regularly incrementing values. You provide the start point, the end point, and the step size. ‘np.linspace’, on the other hand, allows you to specify the number of evenly spaced values to generate within a specified interval. The end point is inclusive by default.
Question: What is the use of the ‘reshape’ method?
Answer: The ‘reshape’ method in NumPy is used to give a new shape to an array without changing its data. It allows you to reorganize the array elements in a new shape while maintaining the order. The new shape must be compatible with the size of the original array.
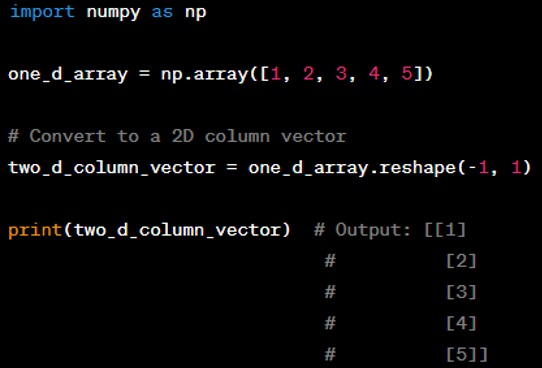
Question: How do you convert a 1D array into a 2D array in NumPy?
Answer: You can convert a 1D array into a 2D array using the ‘reshape’ method. You would specify the new dimensions in the reshape method. If you want to convert it to a column vector, you would use ‘(-1, 1)’ where ‘-1’ tells NumPy to automatically calculate the number of rows.
Question: Can you explain the concept of a universal function (ufunc) in NumPy?
Answer: A universal function, or ufunc, in NumPy is a function that operates on ‘ndarrays’ in an element-by-element fashion, supporting array broadcasting, type casting, and several other standard features. That is, a ufunc takes scalar inputs and produces scalar outputs. The vectorized nature of ufuncs makes them extremely fast and efficient. Examples of ufuncs include mathematical operations like ‘add’, ‘subtract’, ‘multiply’, and ‘divide’, as well as trigonometric functions, bitwise operations, comparison operations, and more.
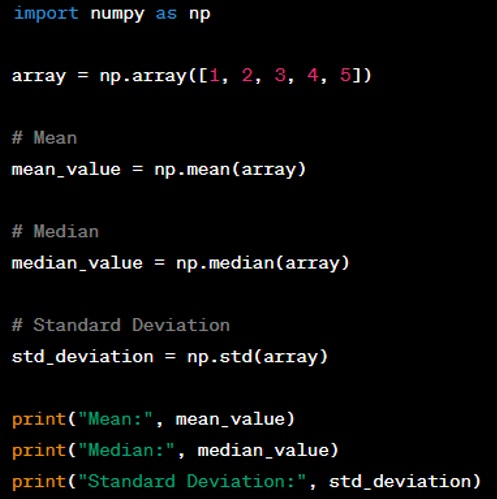
Question: How would you calculate the mean, median, and standard deviation of a NumPy array?
Answer: You can calculate these statistical measures using NumPy functions as follows:
Question: What is a masked array in NumPy?
Answer: A masked array is an array that may have missing or invalid entries. In NumPy, the ‘numpy.ma’ module provides a nearly work-alike replacement for NumPy that supports data arrays with masks. In a masked array, you can mask certain values that are not to be used in computations, whether because they are invalid, missing, or for any other reason.
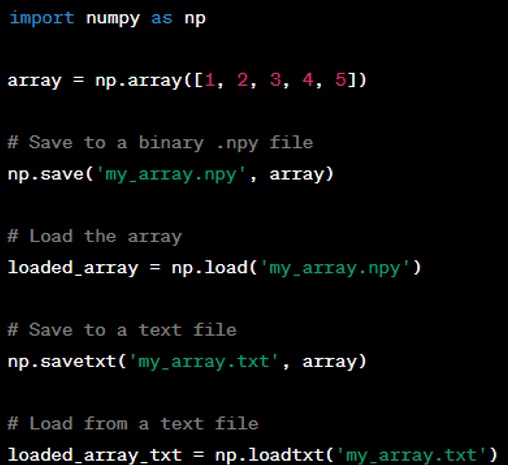
Question: How do you save a NumPy array to a file, and how do you load it?
Answer: NumPy arrays can be saved to a binary file with ‘.npy’ extension using ‘np.save’ and can be loaded using ‘np.load’. For text files, you can use ‘np.savetxt’ and ‘np.loadtxt’. Here is an example:
Question: Can you perform SQL-like operations using NumPy?
Answer: NumPy itself does not provide functions for SQL-like operations. It is primarily for numerical computation on arrays and matrices. However, you can perform similar operations by using boolean indexing, fancy indexing, and other NumPy methods to filter, order, and manipulate data in an array. For operations that are inherently relational database operations, such as joins or grouped aggregations, you would typically use libraries built on top of NumPy like pandas, which provide a more SQL-like interface and functionality.
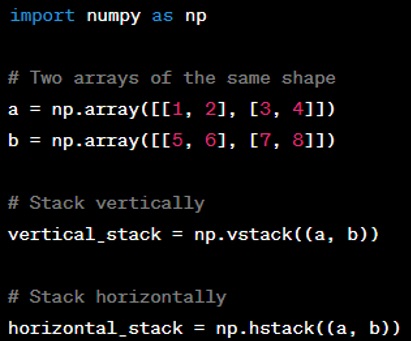
Question: How do you stack multiple NumPy arrays?
Answer: Stacking in NumPy is done using various functions depending on the dimension on which you want to stack the arrays. For example:
- ‘numpy.vstack(tup)’: Stacks arrays in sequence vertically (row-wise).
- ‘numpy.hstack(tup)’: Stacks arrays in sequence horizontally (column-wise).
- ‘numpy.dstack(tup)’: Stacks arrays in sequence depth wise (along the third dimension).
- ‘numpy.concatenate((a1, a2, ...), axis)’: Joins a sequence of arrays along an existing axis.
Here's a code example that stacks two 2D arrays vertically and horizontally:
Question: What are some of the main differences between NumPy arrays and pandas Series/DataFrames?
Answer: NumPy arrays and pandas Series/DataFrames are both powerful tools for data manipulation but serve different purposes:
- Homogeneity: NumPy arrays are homogeneous, meaning they can contain data of one type only, while pandas Series can be heterogeneous but each Series within a DataFrame is of one type.
- Size Mutability: NumPy arrays have a fixed size and require reallocation to change the size. Pandas DataFrames are size-mutable, meaning columns can be inserted and deleted.
- Indexing: Pandas provides more powerful indexing capabilities, like label-based indexing, which is not available in NumPy.
- Functionality: Pandas provides built-in functions for data manipulation (e.g., ‘groupby’, ‘pivot’, etc.), while NumPy focuses on numerical and array computations.
- Performance: NumPy is generally faster for numerical operations due to its underlying implementation.
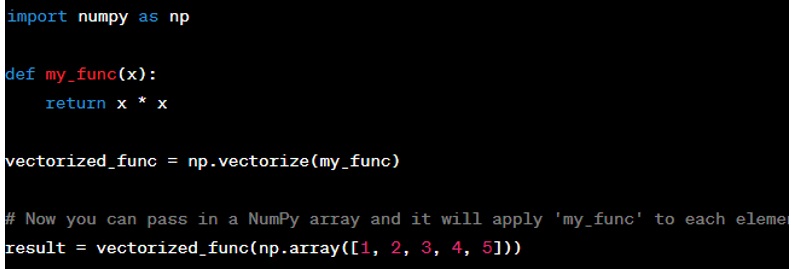
Question: How do you vectorize a function in NumPy?
Answer: Vectorization in NumPy is the process of applying a function to all elements in an array without writing an explicit loop. This is done using NumPy's vectorized functions which are pre-compiled C functions. You can also vectorize your own function using ‘numpy.vectorize’. Here is an example:
Question: What is the difference between ‘numpy.ravel()’ and ‘numpy.flatten()’?
Answer: Both ‘numpy.ravel()’ and ‘numpy.flatten()’ are used to convert a multi-dimensional array into a one-dimensional array. The difference is that ‘ravel()’ returns a view of the original array whenever possible (affecting the original array if the flat array is modified), whereas ‘flatten()’ returns a copy of the original array, ensuring that the original array is not affected by changes to the flat array.
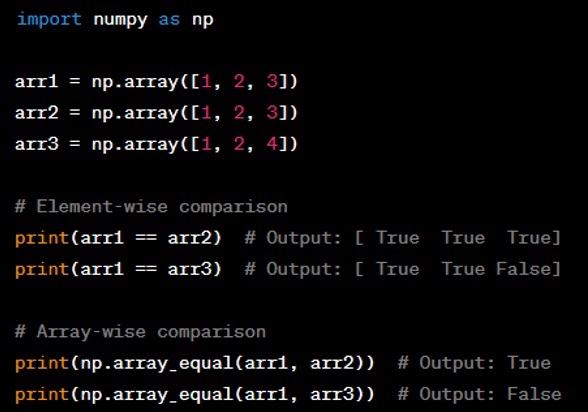
Question: How can you compare two NumPy arrays for equality?
Answer: You can compare two NumPy arrays for element-wise equality using the ‘==‘ operator. To check if two arrays are identical in all elements, use ‘numpy.array equal(arr1, arr2)’. For comparing with a tolerance for floating-point errors, use ‘numpy.allclose(arr1, arr2, atol=tolerance)’. Here's an example:
Question: Can you explain the memory layout of a NumPy array (C-order vs. F-order)?
Answer: NumPy arrays can be stored in memory in two ways: row-major order (C-order) or column-major order (F-order), referring to the C programming language and Fortran language, respectively. In C-order, the last axis index changes the fastest, and the first axis index changes the slowest. This means that if you iterate over the array, you will access consecutive elements in the last dimension first. In F-order, the first axis index changes the fastest, and the last axis index changes the slowest, meaning iteration happens over the columns first. This memory layout affects the performance of various operations due to the way modern CPUs access memory in blocks.
Question: How do you create a record array in NumPy?
Answer: A record array in NumPy allows you to have heterogeneous types, which means each column can be of a different type, similar to structured arrays. You can create a record array using ‘numpy.rec.array’ or by specifying the ‘dtype’ as a list of tuples containing the name and the type of each column.
Here's an example:

Question: What are strides in a NumPy array?
Answer: Strides are a tuple of bytes to step in each dimension when traversing an array. A stride determines how many bytes one needs to skip in memory to go to the next element. If you have a 2D array where each element is 4 bytes (e.g., a float32), the stride for the rows might be 4 times the number of columns, and the stride for the columns would be 4 bytes.
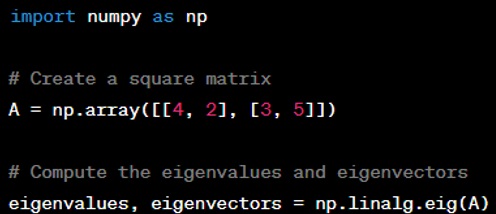
Question: How do you compute the eigenvalues and eigenvectors of a matrix in NumPy?
Answer: You can compute the eigenvalues and eigenvectors of a square matrix in NumPy using the ‘numpy.linalg.eig’ function. Here's how you would do it:
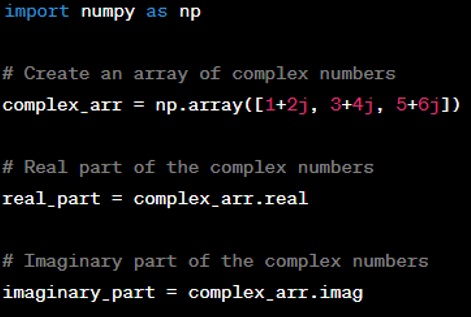
Question: How do you handle complex numbers in NumPy?
Answer: NumPy can handle complex numbers using the ‘complex’ data type (‘complex64’, ‘complex128’). You can perform arithmetic with complex numbers as with real numbers using NumPy arrays. For example:
Question: Can you explain the difference between ‘numpy.dot()’ and ‘numpy.multiply()’?
Answer: ‘numpy.dot()’ performs a dot product of two arrays. For 1-D arrays, it computes the inner product of vectors. For 2-D vectors, it is equivalent to matrix multiplication, and for N-D, it is a sum product over the last axis of the first array and the second-to-last of the second array. In contrast, ‘numpy. multiply()’ performs element-wise multiplication of arrays (of the same shape), multiplying corresponding elements in the arrays.
Question: How do you create an identity matrix in NumPy?
Answer: You can create an identity matrix using ‘numpy.identity()’ or ‘numpy.eye()’. The ‘identity’ function creates a square identity matrix, and ‘eye’ can be used to create an identity matrix of non-square shape. Here's how you can use them:

Question: What is the purpose of the ‘numpy.pad()’ function?
Answer: The ‘numpy.pad()’ function is used to pad arrays with values along the specified axis. You can specify the pad width and the mode of padding (constant values, replicate last value, reflect, wrap, etc.). It is useful for increasing the dimensions of an existing array and for adding borders or margins to the array.
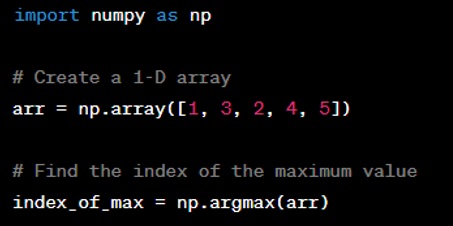
Question: How do you find the index of the maximum value in a NumPy array?
Answer: To find the index of the maximum value in a NumPy array, you use the ‘numpy.argmax()’ function, which returns the indices of the maximum value along the specified axis.
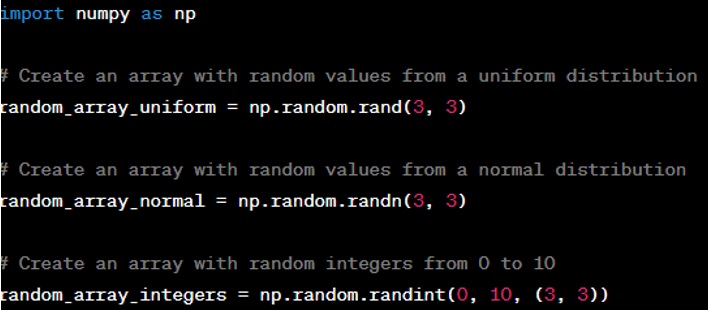
Question: How do you create a NumPy array with random values?
Answer: NumPy provides the ‘numpy.random’ module to create arrays with random numbers. You can use ‘numpy.random.rand()’ for uniform distribution between 0 and 1, ‘numpy.random.randn()’ for standard normal distribution, and ‘numpy.random.randint()’ for random integers within a specific range. Here's an example:
Question: What is the difference between ‘numpy.where()’ and ‘numpy.select()’?
Answer: ‘numpy.where()’ is used to return elements chosen from either ‘x’ or ‘y’ depending on a condition. It's like a vectorized form of the ternary expression ‘x if condition else y’. If only the condition is given, ‘numpy.where()’ returns the indices where the condition is ‘True’.
‘numpy.select()’ is used when you have multiple conditions and multiple choices. It allows you to select from a list of possible values determined by a list of conditions. It's like a vectorized series of ‘if-elif-else’ statements.
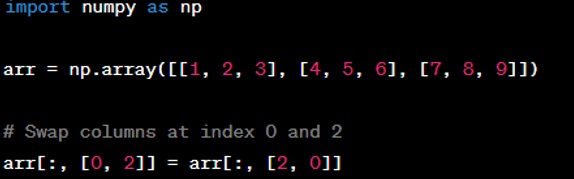
Question: How do you swap two columns in a 2D NumPy array?
Answer: To swap two columns in a 2D NumPy array, you simply reassign the columns by indexing. Here's an example:
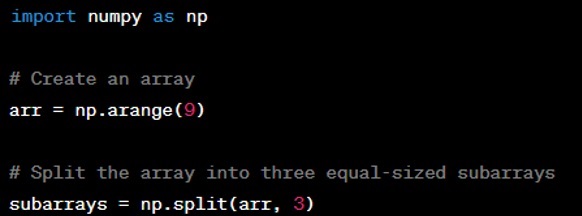
Question: Can you explain the use of the ‘numpy.split()’ function?
Answer: The ‘numpy.split()’ function divides an array into multiple sub-arrays of equal or near-equal sizes. You need to specify the array you want to split and the number of splits or the indices at which to split. Here's an example:
ReadioBook.com