
Chapter 2: Generative AI Data Scientist Second Interview Round.
Introduction: Introduction: Second Round Interview with Rohini Jain.

Anupam: Rohini, welcome to the second round of interviews. Today, we'll focus on practical problems and coding exercises. Are you ready to get started?
Rohini: Yes, Anupam, I'm ready. Looking forward to the challenges.
Anupam: Great. Let's begin with a coding task. Could you write a Python function that takes a DataFrame and returns the names of columns that have more than 20% missing values?
Rohini: Sure, here's a function that should do that:

Anupam: That looks good. Now, imagine you're working with a large dataset that won't fit into memory. How would you use Python to preprocess and summarize this dataset?
Rohini: I would use Dask for out-of-core computing or chunk processing with Pandas. Here's how I might approach it with Pandas:

Anupam: Nice strategy. Could you demonstrate how you would implement a REST API in Flask that serves predictions from a machine learning model?
Rohini: Certainly. Here's a simple Flask app with a REST API endpoint for predictions:

Anupam: Looks good. Now, let's say you're working with time series data. How would you handle seasonality in a dataset using Python?
Rohini: I would decompose the time series to separate the seasonal component using the ‘seasonal_decompose’ method from ‘statsmodels’. Here's an example:

Anupam: Can you write a Python function that takes in a string of text and returns the top 3 most frequent words in the text?
Rohini: Sure, here's a simple function that does that:

Anupam: How would you use Docker to containerize a machine learning application?
Rohini: I would create a ‘Dockerfile’ that specifies the base image, sets up the environment, installs the necessary dependencies, copies the application code into the container, and sets the command to run the app. Here's an example of what the ‘Dockerfile’ might look like:

Anupam: If you needed to scale this application, how would you approach that using Kubernetes?
Rohini: In Kubernetes, I would define a deployment that specifies the number of replicas for the application. Kubernetes can automatically handle the scaling and load balancing. Here's an outline of the steps:
- Create a deployment YAML file that defines the desired state, including the Docker image to use, the number of replicas, and configuration details. - Use kubectl to apply the deployment to the Kubernetes cluster.- Monitor the deployment's status and adjust the number of replicas as needed, which can be automated based on metrics like CPU usage or memory.
Anupam: Can you explain the concept of test-driven development and how you would apply it in a machine learning context?
Rohini: Test-driven development (TDD) is a software development process where you write tests for a function before you write the code to implement it. In machine learning, this might mean writing tests for data preprocessing, model training, and prediction functions before implementing these functions.
This ensures that each piece functions correctly and meets the requirements.
Anupam: How would you go about selecting the right model for a text classification problem?
Rohini: I would start with a baseline model like Naive Bayes or Logistic Regression. I would then experiment with more complex models like SVM, Random Forest, or neural networks if the baseline's performance is unsatisfactory. It's essential to consider the trade-offs between model complexity, training time, interpretability, and performance.
Anupam: Can you demonstrate how you would use TensorFlow to build a simple neural network for a classification problem?
Rohini: Certainly. Here's a basic example using TensorFlow's Keras API:

Anupam: Suppose you have a model that is underperforming. How would you use regularization to improve its performance?
Rohini: If a model is underperforming due to high variance, I would consider adding regularization terms like L1 or L2, which penalize large weights. In Keras, this can be done by adding the ‘kernel_regularizer’ argument to the layers. Here's an example with L2 regularization:

Anupam: How do you approach solving a problem where you need to predict a continuous value instead of a class?
Rohini: For predicting continuous values, I would approach it as a regression problem. I would choose a regression model like linear regression, decision trees, or neural networks with a linear activation function in the output layer. The choice of model would depend on the complexity of the relationship between features and the target variable.
Anupam: Finally, can you tell me about a time when you implemented a machine learning model that required custom data preprocessing?
Rohini: In a project involving image data, I needed to implement custom preprocessing to normalize the images and perform data augmentation to increase the diversity of the training set. I wrote custom functions to adjust the brightness, add noise, and rotate the images, which helped improve the robustness of the model.
Anupam: Moving on to more nuanced aspects of machine learning, could you explain how you would approach feature selection in a high-dimensional dataset?
Rohini: In a high-dimensional dataset, I would use techniques like Principal Component Analysis (PCA) for dimensionality reduction, or model-based methods like Lasso regression that can select features by penalizing the coefficient of less important features to zero. I might also use tree-based methods to rank features by importance.
Anupam: Suppose you're working with a skewed dataset. How would you evaluate your model's performance?
Rohini: With a skewed dataset, accuracy isn't a reliable metric. Instead, I would look at the confusion matrix, precision, recall, F1-score, and ROC curves to evaluate model performance. In particular, the area under the ROC curve (AUC) can be a helpful metric when dealing with skewed datasets.
Anupam: How do you handle missing data when preparing a dataset for a machine learning model?
Rohini: My approach depends on the nature of the missing data. If the missingness is random, I might impute values using mean, median, or mode, or predict missing values with a model. If it's not random, I might delve deeper to understand the missing pattern before deciding on the best strategy.
Anupam: Can you discuss a time when you had to choose between two or more machine learning algorithms for a project?
Rohini: In a project on customer segmentation, I had to choose between k-means and hierarchical clustering. I evaluated both algorithms on silhouette score and decided on k-means due to its scalability and efficiency for the large dataset we had.
Anupam: What methods do you use to ensure that your model generalizes well to new data?
Rohini: To ensure generalization, I use cross-validation during the training process. I also keep a portion of the data as a hold-out set to simulate how the model would perform on new data. Regularization techniques and ensembling methods can also help improve model generalization.
Anupam: Can you provide an example of how you've used a machine learning model to drive business decisions?
Rohini: I developed a predictive maintenance model that used machine learning to predict equipment failure. The model's insights allowed the company to perform maintenance only when necessary, reducing downtime and saving on maintenance costs.
Anupam: Explain a complex machine learning concept in layman's terms.
Rohini: Let's take the concept of overfitting. Imagine you're trying to identify a fruit by learning from examples. If you focus too much on the examples you've seen, like a banana with a tiny brown spot, and think all bananas must have that spot, you're overfitting. It's about finding the right balance between specific and general characteristics.
Anupam: How do you stay informed about the latest research in machine learning?
Rohini: I regularly read papers on arXiv, follow key researchers on Twitter, participate in discussions on Reddit's Machine Learning community, and attend webinars and conferences. Keeping a network with peers in the field also helps exchange the latest findings.
Anupam: Have you ever had to deal with a large-scale data problem? How did you approach it?
Rohini: Yes, I worked on a project that involved processing terabytes of data. I used Apache Spark for its ability to handle large-scale data processing in a distributed manner. I also optimized the Spark jobs by tweaking configurations and using the right transformations to minimize shuffle operations.
Anupam: Can you describe your experience with any machine learning model deployment frameworks?
Rohini: I have experience with MLflow for managing the machine learning lifecycle, including experimentation, reproducibility, and deployment. It's particularly helpful for tracking experiments, packaging code into reproducible runs, and deploying models to production.
Anupam: How would you explain the trade-off between bias and variance?
Rohini: Bias is the error due to overly simplistic assumptions in the learning algorithm. Variance is the error due to too much complexity in the learning algorithm. Ideally, you want a model that's just right, capturing the true patterns without being swayed by noise in the data—a balance between bias and variance.
Anupam: Have you worked with NLP models that go beyond simple text classification? If so, what was the task and how did you approach it?
Rohini: Yes, I worked on a sentiment analysis project that required understanding the context in customer reviews. I used a BERT-based model, which is adept at capturing context within the text. It was a more nuanced task than classification, requiring fine-tuning the model on domain-specific data.
Anupam: What is your approach to debugging a machine learning model that isn't performing as expected?
Rohini: My approach involves several steps: I first ensure the data is correctly processed and features are engineered properly. Then I check the model's assumptions and the fit of the model to the training data. I also look at learning curves to identify if the issue is due to underfitting or overfitting and adjust accordingly.
Anupam: Describe a project where you used machine learning to improve a product or service.
Rohini: I worked on improving a recommendation engine for an e-commerce platform. By integrating collaborative filtering with content-based filtering, the model provided more personalized recommendations, which led to an increase in user engagement and sales.
Anupam: How would you implement a machine learning algorithm from scratch?
Rohini: Implementing an algorithm from scratch involves understanding the underlying mathematics and translating that into code. I typically start with a simple version of the algorithm, test it on a small dataset, and iteratively refine the implementation, adding optimizations and efficiencies as needed.
Anupam: Can you talk about a time when you used graph analytics in a project?
Rohini: In a project for a social media platform, I used graph analytics to identify influential users. I constructed a graph where nodes were users and edges represented interactions. I then used algorithms like PageRank to measure user influence.
Anupam: How do you determine if a machine learning project is feasible or not?
Rohini: I assess feasibility based on data availability, the clarity of the problem statement, the potential impact on the business, and resource availability. I also consider technical constraints and whether the project aligns with the company's strategic goals.
Anupam: How do you approach optimizing a model's hyperparameters?
Rohini: I start with grid search or random search for an initial understanding of the hyperparameter space. Depending on the results and computational resources, I may move to more sophisticated methods like Bayesian optimization for finer tuning.
Anupam: Can you describe your process for validating the results of a natural language processing system?
Rohini: I validate NLP systems by assessing their performance on a set of manually annotated test data. I use metrics relevant to the task, like BLEU for translation or F1 for information extraction. I also conduct qualitative analysis by inspecting the outputs and considering user feedback.
Anupam: Have you ever had to reduce the dimensionality of a dataset? What methods did you use, and why?
Rohini: Yes, I've used PCA for reducing dimensionality in a dataset with many correlated features. It was effective in reducing the feature space while retaining most of the variance. I've also used t-SNE for visualization purposes to understand the data's structure at a high level.
Anupam: Tell me about a time when you had to quickly learn a new technology or tool for a project.
Rohini: For a project requiring real-time analytics, I had to quickly learn Apache Kafka for streaming data processing. I dedicated time to go through the documentation, tutorials, and set up a small prototype to understand its operation and integration with the existing data pipeline.
Anupam: How do you ensure that your machine learning models are not violating privacy or ethical guidelines?
Rohini: I always start by understanding the legal and ethical implications of the data and the model's application. I ensure that the data is anonymized and that the model's decisions are fair and unbiased. I also stay updated with the company's policies and industry regulations regarding data privacy and ethics.
Anupam: Let's dive into some more hands-on problems. Could you write a Python function that normalizes a list of numerical values between 0 and 1?
Rohini: Certainly, here's a simple function that does that:
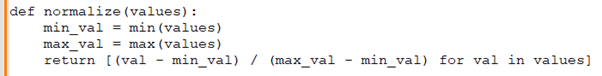
Anupam: Great. Can you show me how you would handle categorical variables in a dataset before feeding it into a machine learning model?
Rohini: Of course. If the categorical variables are nominal, I would use one-hot encoding. Here's an example using pandas:

Anupam: Can you demonstrate a Python function that calculates the Mean Squared Error (MSE) between two lists?
Rohini: Sure, here's a function that calculates the MSE:
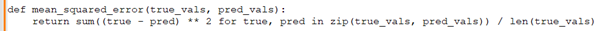
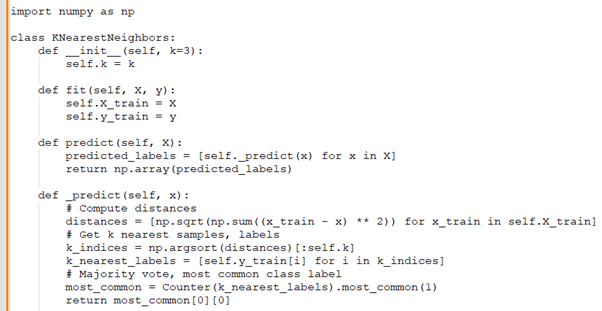
Anupam: How would you implement a Python class for a k-Nearest Neighbors (k-NN) algorithm from scratch?
Rohini: Here's a simple implementation of a k-NN class:
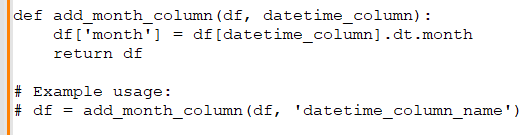
Anupam: Suppose you have a Pandas DataFrame with datetime values. How would you extract the month and add it as a new column?
Rohini: Here's how you can extract the month from a datetime column and add it as a new column:
Anupam: Can you show how you would apply a lambda function to a column in a DataFrame to replace all values above a certain threshold with the mean value of the column?
Rohini: Sure, here's how to do that:

Anupam: How would you use scikit-learn to perform a train-test split on a dataset?
Rohini: You can use the ‘train_test_split’ function from scikit-learn like this:

Anupam: Can you demonstrate how to serialize a trained machine learning model using joblib?
Rohini: Certainly, here's how you would do it:

Anupam: Write a Python snippet to plot the ROC curve for a classification model using Matplotlib.
Rohini: Here's a snippet that uses Matplotlib to plot an ROC curve:

Anupam: How would you use Python to identify and remove constant features from a DataFrame?
Rohini: You can do this by checking for columns with a standard deviation of zero:

Anupam: Can you write a Python function to calculate the Gini index for a set of labels?
Rohini: Here's a function to calculate the Gini index:

Anupam: Show me how you would implement a simple text preprocessor in Python to clean and tokenize text.
Rohini: Here's a simple text preprocessor:

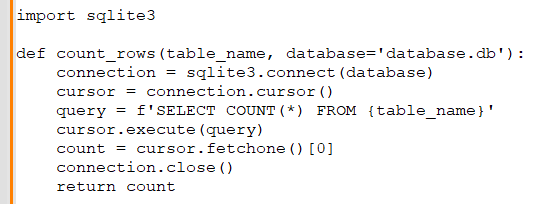
Anupam: Write a Python script that connects to a SQL database and executes a query to count the number of rows in a table.
Rohini: Here's a script that connects to a SQL database and executes a count query:
Anupam: Can you show me how to perform grid search for hyperparameter tuning in scikit-learn?
Rohini: Sure, here's an example using ‘GridSearchCV’:

Anupam: How would you visualize the distribution of a numerical variable using Seaborn?
Rohini: You can use the ‘distplot’ function to visualize the distribution:

Anupam: Write a Python snippet to create a confusion matrix for a classification model's predictions using scikit-learn.
Rohini: Here's how you can create a confusion matrix:

Anupam: If you had to scale a feature to have a mean of 0 and a standard deviation of 1, how would you do that in Python?
Rohini: You would use the ‘StandardScaler’ from scikit-learn like this:

Anupam: Demonstrate how to use Plotly to create an interactive scatter plot.
Rohini: Here's a basic example with Plotly:

Anupam: How would you apply a function to a column in a Pandas DataFrame that replaces all even numbers with 0?
Rohini: You can use the ‘apply’ method with a lambda function:
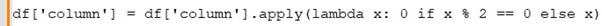
Anupam: Your practical skills in Python and machine learning are quite solid, Rohini. We'll take these exercises into consideration and let you know about the next steps. Thank you for your time.
Rohini: ractical skills in Python and machine learning are quite solid, Rohini. We'll take these exercises into consideration and let you know about the next steps. Thank you for your time.
Anupam: Alright, let's continue with a focus on practical applications. Can you write a function in Python that takes a list of strings and returns a new list with only the strings that contain numbers?
Rohini: Certainly. Here's a function that does just that:

Anupam: Suppose you have an unbalanced dataset. Show me how you would use Python to balance it by undersampling the majority class.
Rohini: Here's one way to perform undersampling in Python:

Anupam: Can you write a Python function that takes an array of predictions and actual values and returns precision, recall, and F1 score?
Rohini: Here's a function that computes those metrics:

Anupam: Demonstrate how you would use pandas to read a CSV file and replace all NaN values with the mean of the column.
Rohini: Here's how you can do that:

Anupam: Let's say you're given a dataset where the date column is in string format. How would you convert it to a datetime object in pandas?
Rohini: You can convert a string to a datetime object using ‘pd.to_datetime’:
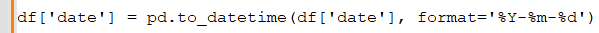
Anupam: How would you use Python to drop all columns from a DataFrame that have a correlation with the target variable greater than 0.9?
Rohini: Here's a snippet that drops highly correlated columns:

Anupam: Can you write a Python function that takes an image file path, loads the image, and converts it to grayscale?
Rohini: Sure, we can use the PIL library for that:

Anupam: If you had to create a simple linear regression model in TensorFlow, how would you approach it?
Rohini: Here's a basic implementation of a linear regression model in TensorFlow:

Anupam: Show me how you would use scikit-learn to encode categorical variables with ordinal encoding.
Rohini: Here's how you can use ‘OrdinalEncoder’ from scikit-learn:

Anupam: Can you explain how you would use cross-validation in a machine learning pipeline?
Rohini: Cross-validation can be integrated into a machine learning pipeline as follows:

Anupam: Finally, how would you use Matplotlib to create a bar chart from a DataFrame?
Rohini: You can create a bar chart with Matplotlib like this:

Anupam: Rohini, your performance in this hands-on session was very impressive. You've demonstrated not just a strong theoretical understanding of data science, but also the practical ability to apply these concepts effectively. It's evident from your coding and problem-solving skills that you're well-prepared to tackle real-world data challenges.
Rohini: Thank you Anupam, it was great to hear. However, I need couple of days to prepare for Data strategy for my next round. I will talk to recruitment team accordingly. Thanks once again.

ReadioBook.com