
Chapter 3: Generative AI Data Scientist Third Interview Round.
Introduction: Third Round Interview with Rohini Jain for the Role of Generative AI Data Scientist at ReadioBook.

Rudraksh:: Good morning, Rohini. Congratulations on making it to the third and final round of interviews. I'm Rudraksh, the Associate Director in the Data Division here at ReadioBook. I oversee the delivery of various data science projects. Today, I want to discuss your technical experience in data engineering and data science to better understand how you would fit into our team.
Are you ready?
Rohini: Good morning, Rudraksh. Thank you for the opportunity. I am ready and looking forward to discussing how I can contribute to the team.
Rudraksh:: Great, let's begin. Can you tell me about a data engineering challenge you faced and how you overcame it?
Rohini: Certainly. In a past project, we had to integrate data from multiple sources with different formats and update frequencies. The challenge was ensuring data quality and consistency. I designed a robust ETL pipeline using Apache Airflow, which allowed for regular data quality checks, transformations, and seamless updates to our data warehouse.
Rudraksh:: That's an insightful experience. How do you ensure the scalability of data processing pipelines you create?
Rohini: Scalability is key. I design pipelines with both horizontal and vertical scaling in mind. I use distributed computing frameworks like Spark for large datasets. I also ensure that the pipeline components, like databases and in-memory data stores, can scale out as required. Code optimization and efficient data structures are also a focus to handle increased loads.
Rudraksh:: In your view, what are the best practices for deploying machine learning models into production?
Rohini: Best practices include rigorous testing, canary releases, A/B testing, and continuous monitoring of model performance. For deployment, I prefer containerization with Docker and orchestration with Kubernetes for ease of scalability and replication. Additionally, I ensure models are versioned and that rollback procedures are in place.
Rudraksh:: How would you approach designing a minimalistic UI for an NLP application?
Rohini: The UI should be user-centric, providing clear visual feedback and intuitive controls for interaction with the NLP system. I would use frameworks like Streamlit or Dash to quickly prototype and deploy a web interface that allows users to input text, visualize results, and even tweak model parameters if needed.
Rudraksh:: Describe your experience with NLP and the design of language models or applications.
Rohini: I have designed NLP models for sentiment analysis and customer feedback classification. My approach includes preprocessing data, utilizing models like LSTM or BERT for understanding context, and fine-tuning them on domain-specific corpora. For applications, I focus on creating RESTful APIs that allow easy integration with other systems.
Rudraksh:: Can you discuss a project where you utilized knowledge graphs?
Rohini: I worked on a project where we developed a knowledge graph to represent relationships between products and components in a manufacturing company. This involved extracting relationships from structured data sources and representing them in a graph database, which then facilitated advanced analytics for the supply chain optimization.
Rudraksh:: How would you deal with memory and latency restrictions when building models for production?
Rohini: I focus on model complexity and data footprint. I prefer using simpler models if they perform comparably to complex ones. Techniques like model pruning, quantization, and knowledge distillation are useful. For latency, I optimize the code and leverage efficient serving frameworks like TensorFlow Serving or ONNX.
Rudraksh:: What's your approach to stakeholder management in a data science project?
Rohini: Clear communication is paramount. I ensure that I understand their needs and set realistic expectations. I provide regular updates and involve stakeholders in key decisions. I also translate technical jargon into business terms to ensure clarity.
Rudraksh:: Describe how you've used machine learning to inform and build business roadmaps.
Rohini: In my last role, I analyzed customer behavior to inform the product development roadmap. Machine learning provided insights into features that customers found valuable, which guided the prioritization of new features in the roadmap.
Rudraksh:: Have you ever had to mentor or manage other data scientists? How do you approach mentorship?
Rohini: Yes, I have mentored junior data scientists. My approach is to provide them with clear guidance while encouraging them to develop their problem-solving skills. I set up regular check-ins to discuss their progress and challenges.
Rudraksh:: How do you stay up-to-date with the latest in AI and machine learning, especially in regard to SoTA models?
Rohini: I follow key AI research journals and conferences like NeurIPS, ICML, and attend webinars and workshops. I also participate in online communities and contribute to open-source projects.
Rudraksh:: Can you walk me through how you would troubleshoot a machine learning model that's not performing as expected?
Rohini: I start by examining the data the model was trained on, checking for issues like class imbalance or data leakage. I then evaluate if the model's complexity is appropriate for the task. I'll also check the training procedure, including parameter tuning and validation strategy.
Rudraksh:: Explain how you would set up a continuous deployment pipeline for an ML project.
Rohini: A continuous deployment pipeline would involve automated testing, building, and deployment. I'd use tools like Jenkins or GitLab CI/CD to automate the pipeline. Tests would include unit tests, integration tests, and model validation tests. Upon passing tests, the model would be containerized and deployed to a production environment.
Rudraksh:: How do you approach designing and developing enterprise solutions that are flexible and extensible?
Rohini: I design solutions with modularity in mind, ensuring components can be added or replaced without disrupting the system. I follow SOLID principles for object-oriented design and ensure there's comprehensive documentation and a clean codebase.
Rudraksh:: Discuss a time when you had to improve complex data flow and database design.
Rohini: In a recent project, the data flow was inefficient, leading to bottlenecks. I redesigned the flow using a combination of streaming and batch processes, which improved throughput. For the database, I normalized the schema to eliminate redundancy, which improved both the performance and the maintainability of the system.
Rudraksh:: How do you incorporate numerical techniques like linear algebra or statistics in building solutions?
Rohini: Numerical techniques are fundamental to transforming raw data into actionable insights. For instance, I've used linear algebra for recommendation systems and statistics for hypothesis testing in A/B testing frameworks.
Rudraksh:: Tell me about your experience with agile practices in the context of data science.
Rohini: Agile practices help in managing data science projects by breaking them down into manageable sprints. My experience includes working with cross-functional teams, iterating quickly based on feedback, and maintaining a backlog of tasks to ensure that we're always working on the highest priority items.
Rudraksh:: How would you handle a situation where the data science solution is not well received by the end-users?
Rohini: I would gather feedback to understand the users' concerns and iterate on the solution. User education might also be necessary to help them understand the value and usage of the solution.
Rudraksh:: Explain how you would implement test-driven development for a new machine learning feature.
Rohini: I'd start by writing tests for the expected behavior of the feature, considering both the happy path and edge cases. The development of the feature would then proceed in small increments, ensuring at each step that the tests pass.
Rudraksh:: Finally, how do you approach improving processes in everyday work within a data team?
Rohini: I encourage regular retrospectives to reflect on what's working and what's not. From there, we can collaboratively identify process improvements. Automation of repetitive tasks and fostering a culture of knowledge sharing are also crucial.
Rudraksh:: Rohini, let's proceed with some scenario-based questions that reflect day-to-day challenges in our field. Can you tell me how you would optimize a SQL query that's running slow, perhaps for a report that's generated daily?
Rohini: To optimize a slow SQL query, I would first examine the execution plan to identify bottlenecks, such as table scans or expensive joins. Indexing is often a quick win, so I’d ensure that the columns used in JOINs, WHERE, and ORDER BY clauses are indexed properly. I’d also consider modifying the query to reduce subqueries and eliminate unnecessary columns from SELECT statements.
Rudraksh:: Imagine you have a dataset with several text fields. How would you preprocess this text data for a machine learning model?
Rohini: Text fields would be tokenized, lowercased, and stripped of punctuation. I’d apply stop word removal to filter out common words that carry less important meaning and use stemming or lemmatization to reduce words to their base forms. For vectorization, I could use TF-IDF or word embeddings depending on the model requirements.
Rudraksh:: In a situation where a model is taking too long to train, what strategies would you use to speed up the process?
Rohini: I’d consider reducing the complexity of the model or the dimensionality of the data. Utilizing a more powerful computing resource or distributed computing could help. I might also use a subset of the data for training or adjust the training algorithm to use mini-batch gradient descent.
Rudraksh:: How would you ensure that a model is not overfitting when you have a small dataset?
Rohini: With a small dataset, I would use cross-validation techniques to maximize the use of available data. Regularization methods can also help prevent overfitting, as can ensemble methods that combine the predictions of several models to reduce variance.
Rudraksh:: Suppose you're given access to a new data source. How do you determine the quality of this data?
Rohini: I’d start by profiling the data to identify missing values, outliers, and inconsistencies. Then, I'd check for data accuracy, timeliness, completeness, and relevance to the problem at hand. It’s also important to evaluate the source of the data for reliability and credibility.
Rudraksh:: Can you describe how you would automate a report that includes visuals and could be sent out to stakeholders regularly?
Rohini: I’d use a combination of a scripting language like Python with a visualization library such as Matplotlib or Seaborn to generate visuals. The script can be scheduled to run at regular intervals using a task scheduler like cron. The report could then be compiled into a PDF and distributed via email using an email library or integrated with a business intelligence tool that supports subscription services.
Rudraksh:: How would you approach creating a REST API for a machine learning model?
Rohini: I’d wrap the machine learning model in a web server using a framework like Flask or FastAPI. The model would be loaded, and an endpoint would be created to receive data, run predictions, and return the results. The API would be containerized with Docker for deployment.
Rudraksh:: If you had to set up a data pipeline for streaming data, what tools would you use and how would you design it?
Rohini: I would use Apache Kafka for data ingestion, Apache Spark for real-time data processing, and a NoSQL database like Cassandra for storing the processed data. The pipeline would be designed to be fault-tolerant and scalable to handle varying loads of data.
Rudraksh:: How do you monitor the health of a machine learning system in production?
Rohini: I’d set up logging for model predictions and monitor the performance metrics against a baseline. I’d also track system-level metrics like latency and throughput. Anomalies in these metrics could trigger alerts for further investigation.
Rudraksh:: Describe your process for updating a live machine learning model with new data.
Rohini: The process involves retraining the model with new data, evaluating it to ensure performance improvements, and then seamlessly deploying it, possibly using a blue-green deployment strategy to minimize downtime and reduce risk.
Rudraksh:: How would you approach designing a recommendation system for a new eCommerce platform?
Rohini: I’d start with collaborative filtering to leverage user-item interactions, complemented by content-based filtering to account for the properties of the items. The system would be designed to continuously learn from user feedback to improve recommendations over time.
Rudraksh:: Can you explain how you would use Git for version control in a collaborative data science project?
Rohini: Git would be used to track changes to the codebase, with a branching model to manage feature development, hotfixes, and releases. Pull requests would facilitate code reviews, and continuous integration could run tests automatically for each change proposed.
Rudraksh:: Suppose you need to visualize the performance of several machine learning models. Which tool would you use and how?
Rohini: I would use Jupyter Notebooks for initial exploration and visualization with libraries like Matplotlib or Plotly. For sharing with stakeholders, I might create interactive dashboards using Dash or Tableau, allowing users to explore the results dynamically.
Rudraksh:: How would you explain the importance of A/B testing to a stakeholder with minimal technical background?
Rohini: I’d describe A/B testing as a method to compare two versions of a product to see which one performs better on a specific metric, like click-through rate. It’s similar to a taste test where customers try two different recipes to determine which one they prefer.
Rudraksh:: Discuss a time when you had to clean a particularly large and messy dataset.
Rohini: I worked with a dataset that required extensive cleaning, including handling missing values, erroneous entries, and standardizing categorical variables. I used pandas for manipulation and scikit-learn’s Imputer for handling missing data, which allowed the dataset to be cleaned efficiently.
Rudraksh:: How would you manage a situation where real-time data is required for model predictions?
Rohini: For real-time predictions, I’d ensure the data pipeline is low-latency and the model is lightweight and optimized for speed. I’d use a technology stack that supports real-time processing, like Kafka for streaming and Redis for in-memory data storage.
Rudraksh:: Describe how you would implement feature toggling for a live AI-driven product.
Rohini: Feature toggling involves implementing a system to dynamically turn features on or off without deploying new code. I’d use a feature flagging system where flags can be toggled through a user interface, allowing for controlled rollouts and quick rollbacks if needed.
Rudraksh:: How do you ensure that your data visualizations are effective and easy to understand?
Rohini: I follow best practices in data visualization, like choosing the right chart type for the data, using clear labeling, minimizing clutter, and emphasizing the key message. I also seek feedback to ensure the visualizations are interpretable by the intended audience.
Rudraksh:: Can you discuss your experience with using Kubernetes for deploying data applications?
Rohini: I’ve used Kubernetes to manage containerized data applications, ensuring they’re highly available and scalable. I’ve set up clusters, defined deployment configurations, and managed services to expose the applications.
Rudraksh:: How would you handle data privacy and security when working with sensitive information?
Rohini: Data privacy and security are paramount. I ensure that data is encrypted in transit and at rest, access is controlled with strict IAM policies, and all processing complies with legal frameworks like GDPR. I also advocate for the use of anonymization or pseudonymization techniques where possible.
Rudraksh:: Shifting our focus to knowledge graphs and graph analytics, let's delve into that area of your expertise. Can you tell me about a project where you developed a knowledge graph and what tools you used?
Rohini: In a project aimed at enhancing search functionality for an academic database, I developed a knowledge graph to represent the relationships between papers, authors, and topics. I used Neo4j as the graph database and Cypher as the query language. The graph model allowed for complex queries that were essential for recommending relevant literature based on user search patterns and behaviors.
Rudraksh:: What challenges did you face while working with knowledge graphs and how did you overcome them?
Rohini: The primary challenge was ensuring the quality and consistency of the data being ingested into the graph. I overcame this by implementing a preprocessing pipeline that validated and standardized the data before insertion. Another challenge was designing efficient graph schemas that could scale and perform well under complex queries, which I addressed by iteratively refining the schema based on query performance metrics.
Rudraksh:: How would you integrate graph analytics into a larger data science workflow?
Rohini: Graph analytics can be integrated into a data science workflow at the stage of data exploration and feature engineering. By extracting structured information from unstructured data and leveraging graph algorithms, we can uncover insights like community detection, centrality measures, and pathfinding, which can be used as features for machine learning models or for direct business analytics.
Rudraksh:: Can you describe your process for constructing and querying a knowledge graph to extract insights?
Rohini: The construction of a knowledge graph starts with defining the entities and relationships that are most pertinent to the business problem. Once the schema is designed, data is ingested into the graph database. For querying, I utilize graph-specific languages like Cypher or Gremlin to traverse the graph, applying filters and aggregations to extract the required insights.
Rudraksh:: What tools and libraries do you prefer for graph analytics and why?
Rohini: For graph analytics, I prefer Neo4j for its powerful graph database capabilities and rich ecosystem. For computation and analysis, I find the NetworkX library in Python to be very flexible and user-friendly. When working with big data, Apache Spark's GraphX provides the necessary scalability for graph computations.
Rudraksh:: How do you ensure the performance of graph queries in a production environment?
Rohini: To ensure performance, I use indexing on properties that are frequently queried and optimize graph models to minimize traversal costs. Caching frequently accessed subgraphs and executing regular performance monitoring and query optimization based on the observed metrics are also part of my strategy.
Rudraksh:: Describe a scenario where graph analytics provided a solution that wouldn't have been possible with traditional data analysis techniques.
Rohini: In a fraud detection scenario, traditional data analysis techniques weren't capturing the complex relationships and patterns of fraudulent behavior. By using graph analytics, we were able to identify non-obvious relationships and suspicious patterns through network connections and graph algorithms, which significantly improved the detection rate.
Rudraksh:: How would you approach creating a real-time recommendation engine using graph analytics?
Rohini: For a real-time recommendation engine, I would utilize a graph database that can handle real-time queries efficiently. The graph would represent users, items, and interactions, and I would use algorithms like collaborative filtering and pathfinding to generate recommendations on the fly based on the user's current context and actions.
Rudraksh:: In your experience, what are the best practices for maintaining and updating knowledge graphs?
Rohini: Best practices include establishing a clear data governance framework that outlines data ownership, quality control, and update processes. Automation of data ingestion and validation pipelines is crucial, as is the regular auditing of the graph to ensure its relevance and accuracy.
Rudraksh:: How would you leverage graph embeddings in a machine learning project?
Rohini: Graph embeddings can translate the complex relationships within a graph into a vector space where traditional machine learning models can operate. I would generate embeddings using algorithms like node2vec and use them as features in predictive modeling tasks to capture the structural essence of the graph.
Rudraksh:: Can you talk about a time when graph analytics helped you understand the structure of a complex dataset?
Rohini: In a project involving a social network, graph analytics allowed us to understand the community structure within the network. By applying modularity-based clustering algorithms, we identified tightly-knit communities, influencers within these communities, and the flow of information across the network.
Rudraksh:: Suppose you have to teach graph analytics to a new team member. How would you go about it?
Rohini: I would start with the basics of graph theory and move on to practical exercises using a graph database like Neo4j to solidify the concepts. I'd introduce them to graph algorithms and their applications in real-world scenarios. Collaborative learning on a small project would also be part of the plan to provide hands-on experience.
Rudraksh:: Discuss how you would use natural language processing techniques to populate a knowledge graph.
Rohini: NLP techniques such as named entity recognition and relation extraction can be used to identify entities and their relationships from text data. These extracted pieces of information can then be used to populate a knowledge graph, essentially converting unstructured text into a structured graph format.
Rudraksh:: How do you validate the accuracy of the relationships within a knowledge graph?
Rohini: Validation can be done by cross-referencing the relationships against trusted data sources. Where possible, manual verification by domain experts is also valuable. Additionally, consistency checks and anomaly detection algorithms can be used to identify and correct inaccuracies in the graph.
Rudraksh:: What considerations do you take into account for the security of graph databases?
Rohini: Security considerations include enforcing access controls, encrypting data both in transit and at rest, and conducting regular vulnerability assessments. It's also important to apply the principle of least privilege when granting access to users and services.
Rudraksh:: How would you explain the benefits of graph analytics to a business executive?
Rohini: I would focus on the ability of graph analytics to uncover relationships and patterns that are not discernible through traditional analytics. This can lead to more informed decision-making, the discovery of new opportunities, and the identification of risks or fraudulent activities within the business network.
Rudraksh:: Can you discuss the scalability challenges with knowledge graphs and how you've addressed them?
Rohini: As knowledge graphs grow, they can become difficult to manage and query efficiently. To address scalability, I've implemented sharding, where the graph is partitioned across multiple databases, and used distributed graph processing frameworks to maintain performance as the graph scales.

Rudraksh:: Tell me about a tool or technology you're excited about in the graph analytics space.
Rohini: I'm excited about graph neural networks (GNNs) and how they can be applied to derive insights from graph-structured data. The ability of GNNs to perform deep learning on graphs opens up many possibilities for advanced analytics and predictive modeling.
Rudraksh:: How do you approach the task of graph data modeling to ensure that the graph effectively represents the domain of interest?
Rohini: Effective graph data modeling requires a deep understanding of the domain. I collaborate closely with domain experts to identify key entities and relationships. I use an iterative approach, starting with a simple model and expanding it as more complexity is needed to capture the domain adequately.
Rudraksh:: What strategies do you use to optimize the storage and retrieval of graph data?
Rohini: I optimize storage by using appropriate data types, compressing data when possible, and organizing it to reduce retrieval times. For retrieval, I use indexing and caching strategies, as well as fine-tuning query parameters to fetch only the necessary data.
Rudraksh:: Finally, could you share how you've used graph analytics to drive innovation within a project or organization?
Rohini: Graph analytics was instrumental in a project where we needed to innovate on how we identified connections between users and products. By analyzing user interactions and product co-purchases, we were able to develop a new cross-selling strategy that led to increased sales.
Rudraksh:: Thank you for your comprehensive responses, Rohini. Your expertise in graph analytics and its applications is clear, and your experiences align well with our needs here at ReadioBook. We'll be in touch shortly with our final decision.
Rohini: you for your comprehensive responses, Rohini. Your expertise in graph analytics and its applications is clear, and your experiences align well with our needs here at ReadioBook. We'll be in touch shortly with our final decision.
Rudraksh:: Let's transition to some coding exercises related to knowledge graphs and graph analytics. I'd like you to write a Python function that takes a list of edges in a graph and returns an adjacency list representation.
Rohini: Sure, please check this code.

Rudraksh:: Great. Now, can you show me how you would perform a breadth-first search on a graph starting from a given node?
Rohini: Sure, please check this code.

Rudraksh:: Nice work. Let's say we need to find the shortest path between two nodes in a graph. Could you write a Python function using Dijkstra's algorithm?
Rohini: Sure, please check this code.

Rudraksh:: Well done. For a graph stored as a DataFrame with columns 'source', 'target', 'weight', can you show me how to convert it to a weighted adjacency list using pandas?
Rohini: Sure Rudraksh, please check this code.

Rudraksh:: Moving on, could you write a Python function that uses networkx to detect communities in a graph?
Rohini: Yes Rudraksh, please check this code.

Rudraksh:: Excellent. Now, suppose you have a large graph. How would you efficiently serialize it to a file and then deserialize it back into a graph structure?
Rohini: Sure Rudraksh, please check this code.

Rudraksh:: Let's say you want to visualize a subgraph that includes all neighbors of a given node up to a certain depth. Can you write a function to extract this subgraph and then use Matplotlib to visualize it?
Rohini: I hope below is the code, which you are asking for.
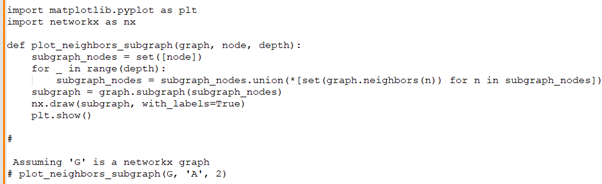
Rudraksh:: Can you demonstrate how to use Neo4j and Cypher to create a knowledge graph from a given list of relationships and entities?
Rohini: Rudraksh, let me write code first and then will show you.

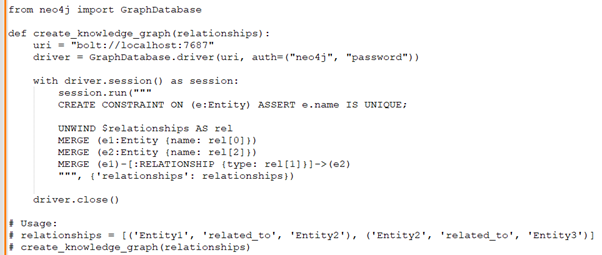
Rudraksh:: Lastly, could you write a Python function that interacts with a graph database to run a query and return the results?
Rohini: I will use neo4j and accordingly will write code.
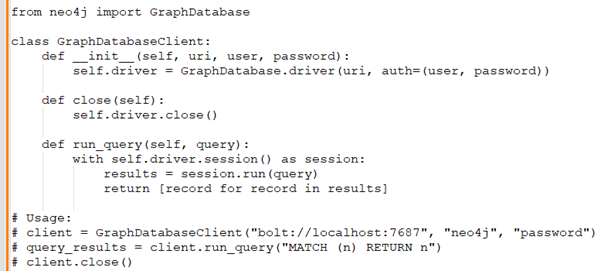
Rudraksh:: Rohini, your problem-solving skills are quite impressive. I have a few more questions, but I must say I'm very much inclined to move forward with you. Let's continue.
Rohini: , your problem-solving skills are quite impressive. I have a few more questions, but I must say I'm very much inclined to move forward with you. Let's continue.
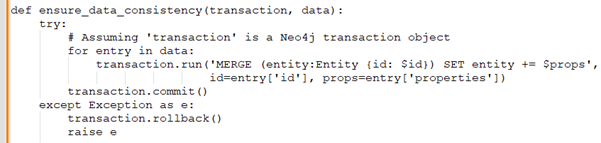
Rudraksh:: How would you go about ensuring data consistency when there are concurrent writes in a graph database?
Rohini: Let me write code, it would take around 5 mins.
Rudraksh:: Can you write a Python function to calculate the PageRank of nodes in a graph?
Rohini: Again it would take 5 mins.

Rudraksh:: Let's say you're working with a massive graph that can't be fully loaded into memory. How would you perform analytics on this graph?
Rohini: For out-of-memory graphs, I would use a disk-based graph system like Neo4j or a distributed graph processing framework like Apache Spark's GraphX. I'd perform analytics in a distributed manner, partitioning the graph and using algorithms optimized for such scenarios.
Rudraksh:: Suppose you want to enrich a knowledge graph with external data sources. What's your strategy for integrating external datasets?
Rohini: I would first identify authoritative and reliable external data sources. Then, I would map the schema of the external dataset to the schema of the knowledge graph. After that, I'd use ETL processes to transform and load the external data into the graph, ensuring entity resolution and de-duplication to maintain data integrity.
Rudraksh:: Can you describe an approach to detect anomalies in a graph?
Rohini: To detect anomalies in a graph, I would compute baseline statistics for typical node and edge attributes. Then, I'd use statistical methods or machine learning to identify outliers. Graph-specific algorithms, like subgraph anomaly detection, can also be used to find patterns that deviate from the norm.
Rudraksh:: How would you optimize graph traversal queries to improve their execution speed?
Rohini: I would index key properties, limit the depth of traversal, and use more efficient algorithms. I would also consider query refactoring, such as breaking down complex traversals into simpler sub-queries and using intermediate results to guide subsequent traversals.
Rudraksh:: Write a Python snippet to merge duplicate nodes in a graph database, assuming the duplicates have a common property.
Rohini:

Rudraksh:: If you had to implement a system to track changes in a graph over time, how would you approach it?
Rohini: I would use a combination of versioning within the graph database and event sourcing. For each change, an event would be recorded, capturing the nature of the change, which can then be applied to the graph to track its state over time.
Rudraksh:: Can you give an example of how you would use machine learning on graph data?
Rohini: One application could be using graph convolutional networks (GCNs) to classify nodes. For example, in a social network graph, we could classify users into different interest groups based on their connectivity patterns and node features.
Rudraksh:: Finally, imagine you've been given a dataset with potential to build a knowledge graph, but it's not structured for that purpose. How would you preprocess and structure it for graph database insertion?
Rohini: I would analyze the dataset to identify entities and relationships. Then, I'd structure the data into graph-compatible formats, such as CSV files that represent nodes and relationships. During the preprocessing, I'd also clean the data and establish a schema that aligns with the graph model.

Rudraksh:: Rohini, thank you for a very engaging and insightful session. It's clear that your skills and experiences are well-aligned with what we're looking for at ReadioBook. I'm confident that you would bring a lot of value to our team and contribute significantly to our ongoing projects.
Rohini: Thank you very much, Rudraksh. I must say, this has been one of the most involved and comprehensive interview processes I've ever been part of. The depth and range of questions challenged me to draw from all areas of my experience and knowledge. It was tough, indeed, but equally rewarding in terms of learning and understanding the expectations here at ReadioBook.
The opportunity to discuss real-world scenarios and hands-on problems has given me valuable insights into the kind of work I can look forward to and the impact I could make. I am very excited about the prospect of joining the team and contributing to the innovative projects ReadioBook is known for. I appreciate the thoroughness of the process, and I am eager to continue the conversation in the HR round. Thank you once again for considering my application. I am looking forward to the next steps.

ReadioBook.com