
Chapter-4: Interview Question for Python Panda.
Introduction: Welcome to ‘ReadioBook.com’ In this chapter we are going to cover questions on Python Pandas Concepts and then we will have some example-based question on the same. Let’s first have some basic intro of Python Panda and why it is being used.
Python's Pandas library is a powerful and widely-used tool for data manipulation and analysis.
It's popular for several key reasons:
- Data Handling: Pandas provides extensive capabilities to work with different types of data – from simple tabular data to time series and more complex structured data. It can read and write data in various formats such as CSV, Excel, JSON, and SQL databases.
- Dataframe Object: The core feature of Pandas is the DataFrame, a two-dimensional, size-mutable, and potentially heterogeneous tabular data structure with labeled axes (rows and columns). It's like a spreadsheet with the power of Python.
- Data Cleaning and Preparation: Pandas makes it easy to clean, transform, and analyze data. Functions for dealing with missing data, merging, joining, data filtration, and transformation are robust and well-integrated.
- Time Series Analysis: Pandas has built-in support for time series functionality, making it easy to work with date and time data.
- Performance: Pandas is built on top of NumPy, a library that provides high-performance arrays. This makes Pandas very fast and efficient for certain types of data operations.
- Community and Ecosystem: As part of the Python ecosystem, Pandas is compatible with many other libraries, like Matplotlib for plotting, Scikit-learn for machine learning, and many more. It also has a large community, providing extensive resources, tutorials, and support.
- Ease of Learning and Use: Pandas syntax is relatively easy to understand and use, especially for those already familiar with Python. This lowers the barrier to entry for data analysis.
- Versatility: From academic research to commercial applications, Pandas is versatile in handling various types of data analysis tasks, making it a go-to tool for data scientists, researchers, and developers. Hence, Pandas is popular because it's a powerful, flexible, and easy-to-use tool that significantly simplifies the process of data analysis in Python, making it accessible to a wide range of users.
Question: What is Pandas in Python and how does it relate to data analysis?
Answer: Pandas is an open-source data manipulation and analysis library in Python. It provides data structures and operations for manipulating numerical tables and time series. Pandas is integral to data analysis in Python because it simplifies the process of data manipulation, cleaning, and exploration. With Pandas, you can efficiently handle large data sets, merge and filter data, perform statistical analyses, and reshape data tables for easier analysis.
Question: Can you explain the difference between a Series and a DataFrame in Pandas?
Answer: In Pandas, a Series is a one-dimensional array-like object that can hold any data type, such as integers, floats, strings, and Python objects. It has an associated array of data labels, called its index. A DataFrame, on the other hand, is a two-dimensional, size-mutable, and potentially heterogeneous tabular data structure with labeled axes (rows and columns). It can be thought of as a container for Series objects that share the same index.
Question: How do you read a CSV file into a Pandas DataFrame?
Answer: You can read a CSV file into a Pandas DataFrame using the ‘read_csv’ function. Here's an example:

Question: What are some ways you can handle missing data in Pandas?
Answer: In Pandas, missing data can be handled in several ways, such as:
- Dropping missing values using the ‘dropna’ method.- Filling missing values using the ‘fillna’ method with a specific value or a computed value (like mean of the column).- Interpolating the missing values using the ‘interpolate’ method, which can perform a variety of interpolations.
Question: How do you select a subset of a DataFrame?
Answer: You can select a subset of a DataFrame using various indexing methods, such as:
- Selecting columns by name: ‘dataframe['column_name']’ or ‘dataframe[['column1', 'column2']]’ for multiple columns.
- Selecting rows by label with the ‘loc’ method: ‘dataframe.loc[label]’.
- Selecting rows by integer location with the ‘iloc’ method: ‘dataframe. iloc[row_index]’.
- Using boolean indexing for conditional selection: ‘dataframe[dataframe['column_name'] > value]’.
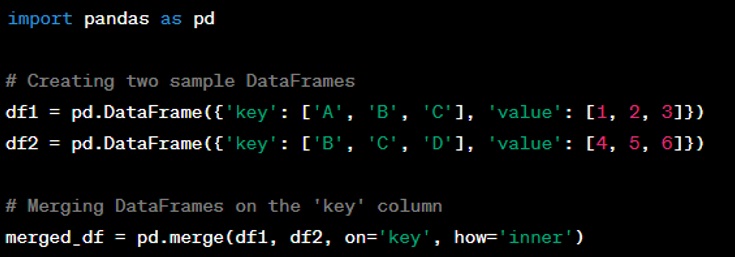
Question: Can you describe how to perform a merge operation between two DataFrames?
Answer: Merging two DataFrames in Python is akin to performing JOIN operations in SQL. Using pandas, you can merge DataFrames using the ‘merge()’ function. The merge can be done on a common column, multiple columns, or on the index. Here's an example:
Question: How do you apply a function to all elements in a DataFrame column?
Answer: To apply a function to all elements in a DataFrame column, you can use the ‘apply()’ method. For example:

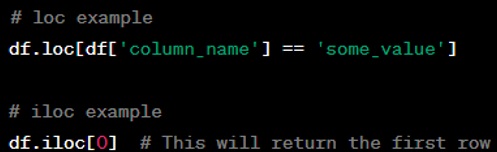
Question: What is the difference between the 'loc' and 'iloc' operators?
Answer: In pandas, ‘loc’ is label-based, which means that you have to specify the name of the rows and columns that you need to filter out. On the other hand, ‘iloc’ is integer index-based, so you have to specify rows and columns by their integer index.
Question: How can you filter data in a DataFrame based on a condition?
Answer: You can filter data in a DataFrame by using boolean indexing. For example, to filter rows where the column 'age' is greater than 30:

Question: What methods are available for reshaping and pivoting a DataFrame?
Answer: Pandas provides various methods for reshaping and pivoting a DataFrame, such as ‘pivot()’, ‘pivot_table()’, ‘melt()’, and ‘stack()’. For example, ‘pivot_table()’ can be used to create a spreadsheet-style pivot table as a DataFrame:

Question: How do you handle duplicate data in a DataFrame?
Answer: To handle duplicates, you can use ‘drop_duplicates()’ method:

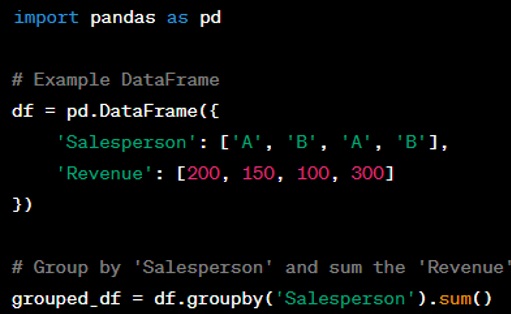
Question: Can you explain the groupby functionality in Pandas?
Answer: The ‘groupby’ functionality in Pandas allows you to group data based on the values of a particular column or a series of columns, and then perform aggregate operations on these groups. This is akin to the SQL group by statement. When you use ‘groupby’, Pandas returns a ‘GroupBy’ object that you can apply functions to, such as sum, count, mean, etc. For example, if you have a DataFrame with sales data, you could group by the 'Salesperson' column to calculate the total sales per salesperson.
Question: What is the purpose of the 'axis' parameter in Pandas methods?
Answer: The 'axis' parameter in Pandas methods specifies the axis along which the operation is performed. ‘axis=0’ refers to the operation being performed along the index, or "down" a column, while ‘axis=1’ refers to the operation being performed along the columns, or "across" a row. For instance, if you want to drop a column, you would set ‘axis=1’, whereas if you want to drop a row, you would set ‘axis=0’.
Question: How can you sort a DataFrame by one or more columns?
Answer: To sort a DataFrame by one or more columns, you use the ‘sort_values’ method and pass the column names that you want to sort by. You can also specify the sorting order for each column by setting ‘ascending’ to either ‘True’ or ‘False’. If sorting by multiple columns, ‘ascending’ can be a list of booleans corresponding to each sorting column.
Question: What are the ways to concatenate two or more DataFrames in Pandas?
Answer: You can concatenate DataFrames in Pandas using the ‘concat’ function, which stacks DataFrames either vertically (one on top of the other) or horizontally (side by side), depending on the ‘axis’ parameter. Another method is to use the ‘merge’ function to join DataFrames on a common key, similar to a SQL join.
Question: How do you deal with categorical data in Pandas?
Answer: Categorical data in Pandas can be handled by converting the data type of a column to 'category' using ‘astype('category')’. This can make the DataFrame more memory-efficient and often faster with certain operations. Additionally, you can use the ‘get_dummies’ method to convert categorical variables into dummy/indicator variables for modeling purposes.
Question: What is the use of the 'inplace' parameter in Pandas functions?
Answer: The ‘inplace’ parameter in Pandas functions allows you to modify a DataFrame in place without having to assign the result back to a variable. If ‘inplace=True’, the DataFrame is modified in place. If ‘inplace=False’ (which is the default), the operation returns a new DataFrame and the original DataFrame remains unchanged.
Question: How do you handle time series data in Pandas?
Answer: Pandas is well-suited for time series data. You can convert a column to datetime using ‘pd.to_datetime’ and then set it as an index, which allows you to use time-based indexing to select data. Pandas also provides a range of time series specific functions like ‘resample’ to aggregate data over time intervals or ‘asfreq’ to convert a time series to a specified frequency. You can also perform time series operations like shifting or window functions for rolling calculations.

Question: What are the advantages of using Pandas Index objects?
Answer: Pandas Index objects facilitate data alignment and fast lookup of information. They are immutable, which means they cannot be modified directly, ensuring data integrity across operations. Indexes also enable automatic alignment of data in arithmetic and join operations, and they support duplicate values. Moreover, using Index objects can lead to performance improvements in lookup and merging operations due to optimized hash tables used under the hood.
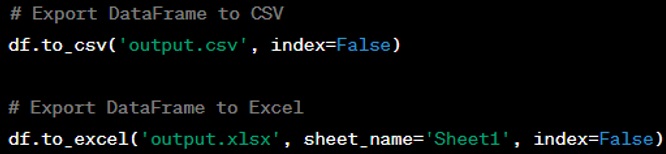
Question: How do you export a DataFrame to a CSV or Excel file?
Answer: To export a DataFrame to a CSV file, you use the ‘to_csv’ method, and to export to an Excel file, you use the ‘to_excel’ method. Both methods allow for various parameters to customize the output, such as specifying the separator in CSV files or choosing the sheet name for Excel files.
Question: Can you explain the concept of chaining methods in Pandas?
Answer: Chaining methods in Pandas means calling multiple methods sequentially, with each method acting on the result of the previous one. This can make your code more readable and concise. However, it's important to be aware that each method call returns a new copy of the DataFrame, so chaining can sometimes lead to increased memory usage.
Question: How do you perform a SQL-style join operation in Pandas?
Answer: SQL-style join operations in Pandas are performed using the ‘merge’ function. You can specify the columns to join on and the type of join to perform (inner, left, right, or outer). For example, if you have two DataFrames with a common key column, you can merge them to combine their data.

Question: What is the Pandas 'pipe' function and when would you use it?
Answer: The Pandas ‘pipe’ function allows you to apply a series of transformations to a DataFrame by passing functions as arguments. It's useful for creating a pipeline of operations, improving readability, and facilitating function reuse. You can use ‘pipe’ to apply your own functions or those from third-party libraries to a DataFrame, passing the result from one function to the next.
Question: How do you convert the data types of DataFrame columns?
Answer: To convert the data types of DataFrame columns, you can use the ‘astype’ method. This method allows you to pass a dictionary specifying the desired data type for each column. It's particularly useful when you need to ensure that data is in the correct format for analysis or to optimize memory usage by choosing more efficient data types.
Question: What is the purpose of the 'applymap' method in Pandas?
Answer: The ‘applymap’ method in Pandas is used to apply a function elementwise to a DataFrame. This is different from ‘apply’, which applies a function along an axis of the DataFrame. ‘applymap’ is best suited for elementwise transformations across the entire DataFrame.

Question: How do you visualize data directly from a DataFrame?
Answer: Pandas integrates with Matplotlib for basic plotting functionality, allowing you to visualize data directly from a DataFrame using the ‘.plot()’ method. You can create various types of plots such as line, bar, histogram, scatter, etc. Pandas plotting is convenient for quick and exploratory analysis.
Question: Can you describe the memory usage of a DataFrame?
Answer: Pandas provides the ‘memory_usage’ method to report the memory consumption of each column in a DataFrame. By default, it shows the memory usage of columns only, but you can use ‘deep=True’ to get a more accurate insight, as it accounts for the full memory usage of object dtypes. The ‘.info()’ method also gives a summary that includes memory usage.
Question: What are some ways to improve the performance of Pandas operations?
Answer: There are several ways to improve the performance of Pandas operations:
- Use Categorical Data Types: Convert object columns that have a relatively small number of unique values to the categorical data type to save on memory and improve performance.
- Avoid Chaining Operations: Chaining methods can lead to intermediate copies of the data, so it's often more efficient to use in-place operations or assign results to variables.
- Use Vectorized Operations: Leverage Pandas' built-in vectorized operations instead of applying functions iteratively.
- Utilize Chunking: If working with very large DataFrames, process the data in chunks rather than loading the entire dataset into memory.
- Increase Available Memory: Sometimes the best way to improve performance is simply to give Pandas more memory, such as by running your code on a machine with more RAM.
- Use Efficient Data Types: Ensure that numeric columns are using the most efficient data types (for example, ‘int32’ instead of ‘int64’ where possible).
- Use Libraries Optimized for Performance: Libraries like Dask or Vaex can handle larger-than-memory datasets and perform computations in parallel.
Question: How do you use multi-indexing or hierarchical indexing in Pandas?
Answer: Multi-indexing, or hierarchical indexing, in Pandas allows you to have multiple index levels on an axis. It provides a way to work with higher dimensional data using a two-dimensional DataFrame. You can create a multi-index DataFrame by using the ‘set_index’ method with multiple columns. Multi-indexes can be used to perform sophisticated data analyses, reshaping, and pivot table operations.

Question: What is the Pandas 'crosstab' function and how do you use it?
Answer: The Pandas ‘crosstab’ function is used to compute a simple cross-tabulation of two (or more) factors. It's basically used to create a bivariate frequency distribution table, showing the frequency or count of combinations that occur within the dataset. This is useful for examining relationships within the data that might not be readily apparent.
Question: How do you aggregate data using the 'pivot_table' method?
Answer: The ‘pivot_table’ method in Pandas creates a spreadsheet-style pivot table as a DataFrame. It allows for data aggregation and summarization. You can specify the columns to group by as index and columns parameters, the values to aggregate, and the aggregation function to use (such as sum, mean, etc. ).

Question: Can you explain the difference between 'copy' and 'view' in Pandas?
Answer: In Pandas, a 'view' is a reference to a DataFrame or Series that reflects changes to the original data, whereas a 'copy' is a new object that can be modified independently of the original data. When slicing a DataFrame, Pandas will often return a view to avoid copying data unnecessarily. However, if you modify the data in a view, the original DataFrame will also be altered. To avoid this, you can explicitly create a copy using the ‘.copy()’ method.
Question: How do you update or modify a DataFrame in place?
Answer: To update or modify a DataFrame in place, you can use various methods without reassigning the DataFrame to a new variable. Some in-place operations include ‘drop’ for removing rows or columns, ‘fillna’ for replacing NaN values, and ‘apply’ or ‘applymap’ for element-wise transformations. Many Pandas methods have an ‘inplace’ parameter that you can set to ‘True’ to apply changes directly to the DataFrame without returning a new object.
Question: What is the use of the 'cut' and 'qcut' functions in Pandas?
Answer: The ‘cut’ function in Pandas is used to segment and sort data values into bins. This function is useful when you need to convert a continuous variable into a categorical variable by binning the data into intervals. You can define your own bin edges and labels.

Question: How do you handle larger-than-memory data with Pandas?
Answer: Handling larger-than-memory data with standard Pandas can be challenging, as Pandas typically requires that the entire dataset fit into memory. However, there are several strategies that you can use to work with such data:
Chunking: Pandas allows you to read data in chunks with a specified chunk size. You can then process each chunk separately.
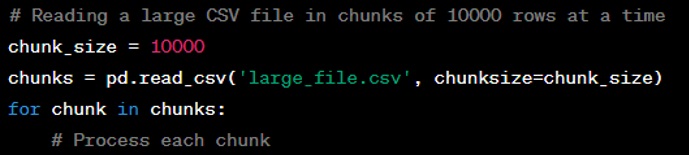
Optimizing Data Types: Convert columns to more memory-efficient data types, for example, using categorical types for string variables with a limited set of values.
Use Dask: Dask is a parallel computing library that integrates with Pandas, providing a way to scale Pandas workflows natively with larger-than-memory computations on distributed systems.
Use Vaex: Vaex is a Python library for lazy Out-of-Core DataFrames (similar to Pandas), which can handle larger-than-memory DataFrames, allowing for the visualization and machine learning on big tabular data.
Database Loading: Load the data into a database and use Pandas to query the database, thus only loading the data needed for analysis into memory.
Sampling: If applicable, work with a sample of the data rather than the full dataset. This allows you to fit a subset of the data into memory.
For handling truly large datasets that cannot fit into memory, using specialized tools like Dask or Vaex is typically the recommended approach.
Question: What is Unicode in Python?
Answer: Unicode is a computing industry standard designed to consistently represent and handle text expressed in most of the world's writing systems. In Python, Unicode is implemented with the ‘str’ type in Python 3.x, allowing for the representation of characters from almost all modern languages and a wide range of symbols. This is a significant improvement over Python 2.x, which provided a separate ‘unicode’ type and used the ‘str’ type for bytes. Unicode is important for writing internationalized applications that can handle various languages and character sets.

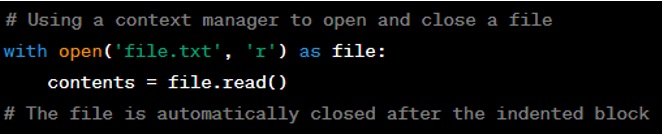
Question: What is a context manager?
Answer: A context manager in Python is a construct that allows for the allocation and release of resources precisely when you want to. The most common way to implement a context manager is through the use of the ‘with’ statement and context manager protocols (‘__enter__’ and ‘__exit__’ methods) or by creating a generator function decorated with ‘@contextlib. contextmanager’. Context managers are widely used for managing resources like file streams, database connections, and locks that need to be explicitly acquired and released.
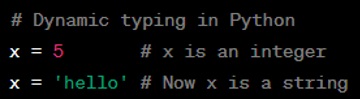
Question: What is a dynamically typed language?
Answer: A dynamically typed language is a programming language in which variables do not have a fixed type. The type of a variable is determined at runtime, not in advance, and can change as the program executes. This means that you can assign different types of values to the same variable without causing an error. Python is an example of a dynamically typed language, which allows for a high level of flexibility but also requires careful testing to avoid runtime errors due to unexpected data types.
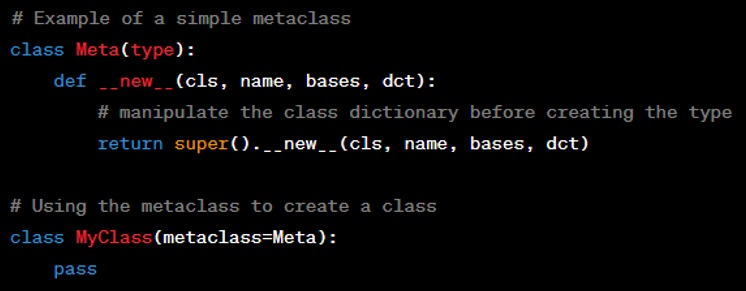
Question: What are metaclasses?
Answer: Metaclasses in Python are a deep and advanced topic; they are classes of classes that define the behavior of a class. A metaclass controls the creation of a class and its instances. In Python, the ‘type’ class is the default metaclass, but you can define your own metaclass by inheriting from ‘type’ and overriding ‘__new__’ or ‘__init__’. Metaclasses can be used to create APIs, enforce coding standards, or modify class attributes dynamically.
Question: What are the bitwise operators in Python?
Answer: Bitwise operators are used to perform operations on binary numbers at the bit level. The main bitwise operators in Python are:
‘&’ (bitwise AND).‘|’ (bitwise OR).‘^’ (bitwise XOR).‘~’ (bitwise NOT).‘<<‘ (left shift).‘>>‘ (right shift).These operators are commonly used in tasks that require manipulation of binary data, such as graphics programming, device driver writing, and low-level network communication.
Question: What are the different modes in file handling?
Answer: When handling files in Python, you can specify different modes for opening a file, which determine the actions you can perform on the file:
‘r’: Read mode, which is the default.
‘w’: Write mode, which will overwrite an existing file or create a new one if it doesn't exist.
‘x’: Exclusive creation mode, which fails if the file already exists.
‘a’: Append mode, which writes to the end of the file if it exists.
‘b’: Binary mode, which is combined with other modes (e.g., ‘rb’, ‘wb’).
‘t’: Text mode, which is the default.
‘+’: Update mode, which allows reading and writing to the same file.
Question: What are the key operations you can perform on a list?
Answer: Lists in Python are versatile and can be modified after their creation. Key operations include:
Adding elements (‘append()’, ‘extend()’, ‘insert()’).Removing elements (‘remove()’, ‘pop()’, ‘clear()’).Finding elements (‘index()’, ‘in’).Counting elements (‘count()’).Sorting (‘sort()’).Reversing (‘reverse()’). Slicing (accessing subsets of the list).
Question: What are the main differences between Python 2 and Python 3?
Answer: Python 3 introduced several changes from Python 2:
- Print statement: Python 2 allowed ‘print "text"‘, whereas Python 3 requires parentheses: ‘print("text")’.
- Integer division: In Python 2, dividing two integers performs floor division; in Python 3, it results in a float.
- Unicode: In Python 2, strings are ASCII by default; in Python 3, they are Unicode.
- xrange: ‘xrange()’ in Python 2 was replaced by ‘range()’ in Python 3 for generating a range of numbers.
- Error handling: Python 3 requires ‘as’ keyword for catching exceptions.
- Libraries: Many libraries that were available in Python 2 have been updated or replaced in Python 3.
- Syntax: Some syntax changes were introduced in Python 3, making it cleaner and more efficient. It should be noted that Python 2 reached its end of life on January 1, 2020, and is no longer maintained. Users are strongly encouraged to migrate to Python 3.
ReadioBook.com